6. Tietokannan suunnittelu
Suunnittelun periaatteet
Tietokannan suunnittelussa meidän tulee päättää tietokannan rakenne: mitä tauluja tietokannassa on sekä mitä sarakkeita kussakin taulussa on. Tähän on sinänsä suuri määrä mahdollisuuksia, mutta tuntemalla muutaman periaatteen pääsee pitkälle.
Hyvä tavoite suunnittelussa on, että tuloksena olevaa tietokantaa on mukavaa käyttää SQL-kielen avulla. Tietokannan rakenteen tulisi olla sellainen, että pystymme hakemaan ja muuttamaan tietoa näppärästi SQL-komennoilla.
Tietokannan suunnittelun periaatteet ovat hyödyllisiä ja johtavat usein toimiviin ratkaisuihin. Kuitenkin aina kannattaa miettiä, mikä periaatteissa on taustalla ja milloin kannattaa mahdollisesti tehdä toisin. Tavoitteen tulisi olla aina se, että tietokanta on käyttötarkoitukseen sopiva, eikä että noudatetaan periaatteita ilman omaa ajattelua.
Taulu vs. luokka
Tietokannan taulu ja olio-ohjelmoinnin luokka ovat samantapaisia käsitteitä. Molemmissa on kyse siitä, että määrittelemme tiedon tyypin. Taulun sarakkeet muistuttavat luokan attribuutteja, ja taulun rivi vastaa luokasta luotua oliota.
Esimerkiksi seuraava SQL-komento ja Python-koodi vastaavat toisiaan:
CREATE TABLE Elokuvat (
id INTEGER PRIMARY KEY,
nimi TEXT,
vuosi INTEGER
);
class Elokuva:
def __init__(self, nimi : str, vuosi : int):
self.nimi = nimi
self.vuosi = vuosi
Huomaa, että luokassa ei ole attribuuttia id, koska ohjelmoinnissa olioilla on viittaukset, joiden avulla ne voidaan yksilöidä.
Rivin lisääminen tietokannan tauluun vastaa uuden olion muodostamista luokasta. Esimerkiksi seuraavat komennot vastaavat toisiaan:
INSERT INTO Elokuvat (nimi,vuosi) VALUES ('Lumikki',1937);
INSERT INTO Elokuvat (nimi,vuosi) VALUES ('Fantasia',1940);
INSERT INTO Elokuvat (nimi,vuosi) VALUES ('Pinocchio',1940);
a = Elokuva("Lumikki",1937)
b = Elokuva("Fantasia",1940)
c = Elokuva("Pinocchio",1940)
Yksi vai useita tauluja?
Ohjelmoinnissa kaikki saman tyyppiset oliot perustuvat samaan luokkaan, ja vastaavasti periaatteena tietokannan suunnittelussa on, että kaikki saman tyyppiset rivit ovat yhdessä taulussa. Tämän ansiosta voimme käsitellä rivejä kätevästi SQL-komennoilla.
Esimerkiksi jos tietokannassa on elokuvia, hyvä ratkaisu on tallentaa kaikki elokuvat samaan tauluun Elokuvat:
id nimi vuosi
---------- ---------- ----------
1 Lumikki 1937
2 Fantasia 1940
3 Pinocchio 1940
4 Dumbo 1941
5 Bambi 1942
Tästä taulusta voimme hakea esimerkiksi vuoden 1940 elokuvat näin:
SELECT nimi FROM Elokuvat WHERE vuosi=1940;
Mutta mitä kävisi, jos jakaisimmekin elokuvat moneen tauluun? Esimerkiksi voisimme jakaa elokuvat tauluihin vuosien mukaan. Tällöin taulussa Elokuvat1940 olisi vuoden 1940 elokuvat, ja voisimme hakea ne näin:
SELECT nimi FROM Elokuvat1940;
Tällainen ratkaisu toimii niin kauan, kuin haluamme hakea vain tietyn vuoden elokuvia. Kuitenkin tietokanta muuttuu vaikeakäyttöiseksi heti, jos haluamme tehdä jotain muita hakuja. Esimerkiksi jos haluamme hakea kaikki elokuvat vuosilta 1940–1950, tarvitsemme useita kyselyjä:
SELECT nimi FROM Elokuvat1940;
SELECT nimi FROM Elokuvat1941;
SELECT nimi FROM Elokuvat1942;
...
SELECT nimi FROM Elokuvat1950;
Kuitenkin kun elokuvat ovat samassa taulussa, niin selviämme yhdellä kyselyllä:
SELECT nimi FROM Elokuvat WHERE vuosi BETWEEN 1940 AND 1950;
Kun elokuvat ovat yhdessä taulussa, pystymme käsittelemään niitä monipuolisesti yksittäisillä SQL-komennoilla, mikä ei olisi mahdollista, jos tauluja olisi useita.
Viittausten toteutus
Ohjelmoinnissa olion sisällä voi olla viittaus toiseen olioon, ja vastaavasti tietokannan taulun rivillä voi olla viittaus toiseen riviin. Kun jokaisella taulun rivillä on pääavaimena id-numero, riveihin on kätevää viitata muualta.
Yksi moneen -suhde
Tarkastellaan tilannetta, jossa tallennamme tietokantaan kursseja ja opettajia. Taulujen välillä on yksi moneen -suhde: jokaisella kurssilla on yksi opettaja, kun taas yhdellä opettajalla voi olla monta kurssia. Pythonissa voisimme luoda luokat näin:
class Opettaja:
def __init__(self, nimi : str):
self.nimi = nimi
class Kurssi:
def __init__(self, nimi : str, opettaja : Opettaja):
self.nimi = nimi
self.opettaja = opettaja
Vastaavasti voimme luoda tietokannan taulut näin:
CREATE TABLE Opettajat (
id INTEGER PRIMARY KEY,
nimi TEXT
);
CREATE TABLE Kurssit (
id INTEGER PRIMARY KEY,
nimi TEXT,
opettaja_id INTEGER REFERENCES Opettajat
);
Taulussa Kurssit sarake opettaja_id viittaa tauluun Opettajat, eli siinä on jonkin opettajan id-numero. Ilmaisemme viittauksen REFERENCES-määreellä, joka kertoo, että sarakkeessa oleva kokonaisluku viittaa nimenomaan tauluun Opettajat.
Voisimme laittaa tauluihin tietoa vaikkapa seuraavasti:
INSERT INTO Opettajat (nimi) VALUES ('Kaila');
INSERT INTO Opettajat (nimi) VALUES ('Kivinen');
INSERT INTO Opettajat (nimi) VALUES ('Laaksonen');
INSERT INTO Kurssit (nimi, opettaja_id) VALUES ('Ohjelmoinnin perusteet',1);
INSERT INTO Kurssit (nimi, opettaja_id) VALUES ('Ohjelmoinnin jatkokurssi',1);
INSERT INTO Kurssit (nimi, opettaja_id) VALUES ('Tietokantojen perusteet',3);
INSERT INTO Kurssit (nimi, opettaja_id) VALUES ('Tietorakenteet ja algoritmit',2);
Monta moneen -suhde
Tarkastellaan sitten tilannetta, jossa useampi opettaja voi järjestää kurssin yhteisesti. Tällöin kyseessä on monta moneen -suhde, koska kurssilla voi olla monta opettajaa ja opettajalla voi olla monta kurssia.
Pythonissa voisimme toteuttaa tämän muutoksen helposti muuttamalla luokkaa Kurssi niin, että siinä on yhden opettajan sijasta lista opettajista:
class Kurssi:
def __init__(self, nimi : str):
self.nimi = nimi
self.opettajat = []
def lisaa_opettaja(self, opettaja : Opettaja):
self.opettajat.append(opettaja)
Tietokannoissa tilanne on kuitenkin toinen, koska emme voi tallentaa järkevästi taulun sarakkeeseen listaa viittauksista. Tämän sijasta meidän täytyy luoda uusi taulu viittauksille:
CREATE TABLE Opettajat (
id INTEGER PRIMARY KEY,
nimi TEXT
);
CREATE TABLE Kurssit (
id INTEGER PRIMARY KEY,
nimi TEXT
);
CREATE TABLE KurssinOpettajat (
kurssi_id INTEGER REFERENCES Kurssit,
opettaja_id INTEGER REFERENCES Opettaja
);
Muutoksena on, että taulussa Kurssit ei ole enää viittausta tauluun Opettajat, mutta sen sijaan tietokannassa on uusi taulu KurssinOpettajat, joka viittaa kumpaankin tauluun. Jokainen rivi tässä rivissä kuvaa yhden suhteen muotoa “kurssilla x opettaa opettaja y”.
Esimerkiksi voisimme ilmaista näin, että kurssilla on kaksi opettajaa:
INSERT INTO Opettajat (nimi) VALUES ('Kivinen');
INSERT INTO Opettajat (nimi) VALUES ('Laaksonen');
INSERT INTO Kurssit (nimi) VALUES ('Tietorakenteet ja algoritmit');
INSERT INTO KurssinOpettajat VALUES (1,1);
INSERT INTO KurssinOpettajat VALUES (1,2);
Huomaa, että voisimme käyttää tätä ratkaisua myös aiemmassa tilanteessa, jossa kurssilla on aina tasan yksi opettaja, joskin tietokannassa olisi silloin tavallaan turha taulu.
Tiedon atomisuus
Periaate: Tietokannan taulun jokaisessa sarakkeessa on yksittäinen eli atominen tieto, kuten yksi luku tai yksi merkkijono. Sarakkeessa ei saa olla listaa tiedoista.
Tämä periaate helpottaa tietokannan käsittelyä SQL-komentojen avulla: kun jokainen tieto on omassa sarakkeessaan, niin pystymme viittaamaan tietoon kätevästi komennoissa.
Kun tietokantaan halutaan tallentaa listoja, luodaan uusi taulu, jossa jokainen rivi on jonkin listan yksittäinen alkio, kuten äskeinen taulu KurssinOpettajat. Mutta miksi emme voisi vain tallentaa listaa yhteen sarakkeeseen? Seuraava esimerkki selventää asiaa.
Esimerkki
Vaihe 1
Haluamme tallentaa tietokantaan opiskelijoiden tenttituloksia. Tentissä on neljä tehtävää, joista voi saada 0–6 pistettä. Voisimme koettaa tallentaa pisteet näin:
id opiskelija_id pisteet
---------- ------------- ----------
1 1 6,5,1,4
2 2 3,6,6,6
3 3 6,4,0,6
Ideana on, että sarakkeessa pisteet on merkkijono, jossa on lista pisteistä pilkuilla erotettuina. Tämä ratkaisu kuitenkin rikkoo periaatetta, että jokaisessa sarakkeessa on yksittäinen tieto. Mitä vikaa ratkaisussa on?
Ratkaisun ongelmana on, että meidän on vaivalloista koettaa päästä pisteisiin käsiksi SQL-komennoissa, koska pisteet ovat merkkijonon sisällä. Esimerkiksi jos haluamme laskea jokaisen opiskelijan yhteispisteet, tarvitsemme seuraavan tapaisen kyselyn:
SELECT opiskelija_id, SUBSTR(pisteet,1,1)+
SUBSTR(pisteet,3,1)+
SUBSTR(pisteet,5,1)+
SUBSTR(pisteet,7,1) FROM Tulokset;
Tässä funktio SUBSTR erottaa merkkijonosta tietyssä kohdassa olevan osajonon. Kysely on kuitenkin hankala ja lisäksi toimii vain, kun pisteitä on tasan neljä ja ne ovat yksinumeroisia. Tarvitsemme paremman tavan tallentaa pisteet.
Vaihe 2
Seuraavassa taulussa pisteille on neljä saraketta, jolloin voimme käsitellä niitä yksitellen:
id opiskelija_id pisteet1 pisteet2 pisteet3 pisteet4
---------- ------------- ---------- ---------- ---------- ----------
1 1 6 5 1 4
2 2 3 6 6 6
3 3 6 4 0 6
Tämän ansiosta saamme jo toteutettua kyselyn mukavammin:
SELECT opiskelija_id, pisteet1+pisteet2+pisteet3+pisteet4 FROM Tulokset;
Tämä ratkaisu on selkeästi parempaan suuntaan, mutta siinä on edelleen ongelmia. Vaikka pisteet ovat eri sarakkeissa, oletuksena on edelleen, että tehtäviä on tasan neljä. Jos tehtävien määrä muuttuu, joudumme muuttamaan taulun rakennetta ja kaikkia pisteisiin liittyviä SQL-komentoja, mikä ei ole hyvä tilanne.
Vaihe 3
Kun haluamme tallentaa listan tietokantaan, hyvä ratkaisu on tallentaa jokainen listan alkio omalle rivilleen. Tämän esimerkin tapauksessa voimme luoda taulun, jonka jokainen rivi ilmaisee tietyn opiskelijan pisteet tietyssä tehtävässä:
id opiskelija_id tehtava_id pisteet
---------- ------------- ---------- ----------
1 1 1 6
2 1 2 5
3 1 3 1
4 1 4 4
5 2 1 3
6 2 2 6
7 2 3 6
8 2 4 6
9 3 1 6
10 3 2 4
11 3 3 0
12 3 4 6
Nyt voimme hakea kunkin opiskelijan yhteispisteet näin:
SELECT opiskelija_id, SUM(pisteet) FROM Tulokset GROUP BY opiskelija_id;
Tämä on yleiskäyttöinen kysely eli se toimii yhtä hyvin riippumatta tehtävien määrästä. Pystymme hyödyntämään summan laskemisessa funktiota SUM sen sijaan, että meidän tulisi luetella kaikki tehtävät itse.
Huomaa, että muutoksen seurauksena taulun rivien määrä kasvoi selvästi. Tätä ei kannata kuitenkaan hätkähtää: tietokantajärjestelmät on toteutettu niin, että ne toimivat hyvin, vaikka taulussa olisi paljon rivejä.
Mikä on atomista tietoa?
Atomisen tiedon käsite ei ole hyvin määritelty. Selkeästi lista ei ole atominen tieto, mutta onko sitten vaikka merkkijonokaan, jossa on useita sanoja?
Tarkastellaan esimerkkinä tilannetta, jossa taulun sarakkeessa on käyttäjän nimi. Onko tämä huonoa suunnittelua, koska samassa sarakkeessa on etu- ja sukunimi?
id nimi
---------- --------------
1 Anna Virtanen
2 Maija Korhonen
3 Pasi Lahtinen
Voisimme myös tallentaa etu- ja sukunimen erikseen näin:
id etunimi sukunimi
---------- ---------- ----------
1 Anna Virtanen
2 Maija Korhonen
3 Pasi Lahtinen
Riippuu tilanteesta, kumpi taulu on parempi. Jos järjestelmässä on erityisesti tarvetta etsiä tietoa etu- tai sukunimen perusteella (esimerkiksi etsiä kaikki käyttäjät, joiden etunimi on Anna), jälkimmäinen taulu on parempi. Kuitenkaan usein ei ole näin eikä ole mitään pahaa tallentaa samaan sarakkeeseen etu- ja sukunimi.
Vastaavasti jos tietokantaan tallennetaan käyttäjän lähettämä viesti, siinä voi olla monia sanoja eli tavallaan viesti on lista sanoja, mutta on silti hyvä ratkaisu tallentaa koko viesti yhteen sarakkeeseen, koska viestiä käsitellään tietokannassa yhtenä kokonaisuutena. Olisi hyvin huono ratkaisu jakaa “atomisesti” viestin sanat omiin sarakkeisiin.
Kannattaakin ajatella asiaa niin, että jos jotain tietoa on tarvetta käsitellä erillisenä SQL-komennoissa, niin se on atominen tieto, jonka tulee olla omassa sarakkeessa. Jos taas tietoon ei viitata SQL-komennoissa, se voi olla sarakkeessa osana laajempaa kokonaisuutta.
Toisteinen tieto
Periaate: Jokainen tieto on tasan yhdessä paikassa tietokannassa. Tietokannassa ei ole tietoa, jonka voi laskea tai päätellä tietokannan muun sisällön perusteella.
Tätä periaatetta seuraamalla tietokannan sisällön päivittäminen on helppoa, koska päivitys riittää tehdä yhteen paikkaan eikä se vaikuta tietokannan muihin osiin.
Esimerkki 1
Tallennamme järjestelmään käyttäjien lähettämiä viestejä seuraavasti tauluun Viestit:
id kayttaja viesti
---------- ---------- --------------
1 Anna123 Missä olet?
2 Joulupukki Bussissa vielä
3 Anna123 Meneekö kauan?
4 Joulupukki 5 min
Tämä on muuten toimiva ratkaisu, mutta tietokannan sisältöä on hankalaa päivittää, jos käyttäjä päättää vaihtaa nimeään. Esimerkiksi jos Anna123 haluaa muuttaa nimeään, muutos täytyy tehdä jokaiseen viestiin, jonka hän on lähettänyt.
Parempi ratkaisu on toteuttaa tietokanta niin, että käyttäjän nimi on vain yhdessä paikassa. Luonteva paikka tälle on taulu Kayttajat, joka sisältää käyttäjät:
id nimi
---------- ----------
1 Anna123
2 Joulupukki
Muissa tauluissa on vain viitteenä käyttäjän id-numero, joka on muuttumaton tieto. Esimerkiksi taulu Viestit näyttää nyt tältä:
id kayttaja_id viesti
---------- ----------- --------------
1 1 Missä olet?
2 2 Bussissa vielä
3 1 Meneekö kauan?
4 2 5 min
Tämän jälkeen käyttäjän nimen muuttaminen on helppoa, koska muutos riittää tehdä taulun Kayttajat yhteen riviin ja muutos päivittyy heti kaikkialle, koska muissa tauluissa viitataan edelleen oikeaan riviin.
Tämä monimutkaistaa kyselyjä, koska meidän täytyy hakea tietoa useista tauluista, mutta ratkaisu on kuitenkin kokonaisuuden kannalta hyvä.
Vieläkin toisteisuutta?
Äskeisestä muutoksesta huolimatta tietokannassa saattaa esiintyä edelleen toisteisuutta. Esimerkiksi seuraavassa tilanteessa käyttäjät lähettävät samanlaisen viestin “Hei!”. Pitäisikö tietokannan rakennetta parantaa?
id kayttaja_id viesti
---------- ----------- --------------
1 1 Hei!
2 2 Hei!
Tässä tapauksessa ei olisi hyvä idea toteuttaa tietokantaa niin, että jos kaksi käyttäjää lähettää saman sisältöisen viestin, viestin sisältö tallennetaan vain yhteen paikkaan.
Vaikka viesteissä on sama sisältö, ne ovat erillisiä viestejä, joiden ei ole tarkoitus viitata samaan asiaan. Jos käyttäjä 1 muuttaa viestin sisältöä, muutoksen ei tule heijastua käyttäjän 2 viestiin, vaikka siinä sattuu olemaan tällä hetkellä sama sisältö.
Esimerkki 2
Tallennamme tietokantaan tietoa opiskelijoiden suorituksista. Tietokannasta voidaan kysyä, montako opintopistettä opiskelija on suorittanut.
Seuraavassa tietokannassa jokaisen opiskelijan yhteyteen on tallennettu tieto, montako opintopistettä hän on suorittanut. Taulun Opiskelijat sisältönä on:
id nimi op
---------- ---------- ----------
1 Maija 20
2 Uolevi 10
Taulussa Suoritukset puolestaan on seuraavat rivit:
id opiskelija_id kurssi_id op
---------- ------------- ---------- ----------
1 1 1 5
2 1 2 5
3 1 4 10
4 2 1 5
5 2 3 5
Tämän ansiosta on helppoa hakea opiskelijan opintopisteiden yhteismäärä:
SELECT op FROM Opiskelijat WHERE nimi='Maija';
Kuitenkin tietokannassa on toisteista tietoa: taulun Opiskelijat sarakkeen op sisältö voidaan laskea taulun Suoritukset avulla. Ongelmana on, että jos lisäämme tai poistamme suorituksen, niin joudumme tekemään muutoksen kahteen eri tauluun. Jos muutos unohtuu tehdä tai epäonnistuu, tietokantaan tulee ristiriitaista tietoa.
Pääsemme eroon toisteisesta tiedosta poistamalla sarakkeen op taulusta Opiskelijat:
id nimi
---------- ----------
1 Maija
2 Uolevi
Tämän muutoksen seurauksena on vaikeampaa selvittää opiskelijan opintopisteet, koska meidän täytyy laskea tieto suorituksista lähtien:
SELECT
SUM(S.op)
FROM
Suoritukset S, Opiskelijat O
WHERE
S.opiskelija_id=O.id AND O.nimi='Maija';
Tämä on kuitenkin kokonaisuutena hyvä muutos, koska nyt voimme huoletta muutella suorituksia ja luottaa siihen, että saamme aina haettua oikean tiedon opiskelijan opintopisteistä.
Muutokset vs. kyselyt
Vaikka ihanteena on, että tietokannassa ei ole toisteista tietoa, joskus kuitenkin toisteista tietoa tarvitaan hakujen tehostamiseksi. Toisteinen tieto vaikeuttaa tietokannan muuttamista mutta helpottaa kyselyjen tekemistä.
Usein esiintyvä ilmiö tietojenkäsittelytieteessä on, että joudumme tasapainoilemaan sen kanssa, haluammeko muuttaa vai hakea tehokkaasti tietoa ja paljonko tilaa voimme käyttää. Tämä tulee tietokantojen lisäksi vastaan esimerkiksi algoritmien suunnittelussa.
Jos tietokannassa ei ole toisteista tietoa, muutokset ovat helppoja, koska jokainen tieto on vain yhdessä paikassa eli riittää muuttaa vain yhden taulun yhtä riviä. Myös hyvänä puolena tietokanta vie vähän tilaa. Toisaalta kyselyt voivat olla monimutkaisia ja hitaita, koska halutut tiedot pitää kerätä kasaan eri puolilta tietokantaa.
Kun sitten lisäämme toisteista tietoa, pystymme nopeuttamaan kyselyjä mutta toisaalta muutokset hidastuvat, koska muutettu tieto pitää päivittää useaan paikkaan. Samaan aikaan myös tietokannan tilankäyttö kasvaa toisteisen tiedon takia.
Ei ole mitään yleistä sääntöä, paljonko toisteista tietoa kannattaa lisätä, vaan tämä riippuu tietokannan sisällöstä ja halutuista kyselyistä. Yksi hyvä tapa on aloittaa tilanteesta, jossa toisteista tietoa ei ole, ja lisätä sitten toisteista tietoa tarvittaessa, jos osoittautuu, että kyselyt eivät muuten ole riittävän tehokkaita.
Suunnitteluesimerkki
Tarkastellaan lopuksi laajempaa esimerkkiä, jossa tavoitteemme on suunnitella tietokanta Facebookin kaltaista yhteisöpalvelua varten. Tietokannan tulee mahdollistaa seuraavat toiminnot:
- Käyttäjä voi kirjautua palveluun antamalla sähköpostiosoitteen ja salasanan.
- Käyttäjällä on oma sivu, johon hän voi lähettää päivityksiä.
- Käyttäjä voi lisätä profiiliinsa tietoa, kuten nimen, syntymäpäivän, asuinpaikan, jne.
- Käyttäjä voi ystävystyä muiden palvelun käyttäjien kanssa.
- Käyttäjä voi lähettää palveluun valokuvia ja valita yhden niistä profiilikuvaksi.
- Käyttäjät voivat tykätä ja kommentoida toistensa päivityksiä ja kuvia.
- Käyttäjät voivat lähettää toisilleen yksityisviestejä.
- Palvelussa on myös ylläpitäjiä, joilla on enemmän oikeuksia kuin muilla käyttäjillä.
Suunnittelun vaiheet
Tietokannan suunnittelu etenee yleensä pikkuhiljaa niin, että tietokantaan lisätään uusia tauluja ja sarakkeita aina, kun uusissa toiminnoissa on tarvetta niille.
Seuraavaksi näemme, miten esimerkkitietokanta rakentuu vaihe vaiheelta vaadittujen toimintojen perusteella.
Kirjautuminen palveluun
- Käyttäjä voi kirjautua palveluun antamalla sähköpostiosoitteen ja salasanan.
Tämä on hyvin tavallinen toiminto, josta on hyvä aloittaa tietokannan suunnittelu. Tarvitsemme taulun, jossa on käyttäjän tunnus (sähköpostiosoite) ja salasana:
CREATE TABLE Kayttajat (
id INTEGER PRIMARY KEY,
tunnus TEXT,
salasana TEXT
);
Päivitykset omalle sivulle
- Käyttäjällä on oma sivu, johon hän voi lähettää päivityksiä.
Tätä toimintoa varten tietokantaan täytyy pystyä tallentamaan käyttäjän päivityksiä. Hyvä ratkaisu on luoda taulu, joka sisältää kaikkien käyttäjien päivitykset id-numeron mukaan:
CREATE TABLE Paivitykset (
id INTEGER PRIMARY KEY,
kayttaja_id INTEGER REFERENCES Kayttajat,
viesti TEXT,
aika DATETIME
);
Huomaa, että tietokantaan ei tarvitse tallentaa tietoa käyttäjän sivusta. Jokaisella käyttäjällä on sivu, joka sisältää käyttäjän päivitykset, mutta sivuun itsessään ei liity tietoa.
Profiilin tiedot
- Käyttäjä voi lisätä profiiliinsa tietoa, kuten nimen, syntymäpäivän, asuinpaikan, jne.
Yksi tapa toteuttaa tämä toiminto olisi laajentaa taulua Kayttajat:
CREATE TABLE Kayttajat (
id INTEGER PRIMARY KEY,
tunnus TEXT,
salasana TEXT,
nimi TEXT,
syntymapaiva DATE,
asuinpaikka TEXT,
...
);
Tämä on sinänsä toimiva tapa, mutta tässä voi tulla ongelmaksi, että profiilissa voi olla paljon vaihtelevaa tietoa, jolloin tauluun Kayttajat tulee suuri määrä sarakkeita. Tämän vuoksi teemme toisenlaisen ratkaisun ja luomme uuden taulun KayttajanTiedot:
CREATE TABLE KayttajanTiedot (
id INTEGER PRIMARY KEY,
kayttaja_id INTEGER REFERENCES Kayttajat,
avain TEXT,
arvo TEXT
);
Nyt käyttäjän tietoja voidaan lisätä tähän tapaan:
INSERT INTO KayttajanTiedot (kayttaja_id, avain TEXT, arvo TEXT)
VALUES (1,'nimi','Maija Virtanen');
INSERT INTO KayttajanTiedot (kayttaja_id, avain TEXT, arvo TEXT)
VALUES (1,'syntymapaiva','2000-01-01');
INSERT INTO KayttajanTiedot (kayttaja_id, avain TEXT, arvo TEXT)
VALUES (1,'asuinpaikka','Helsinki');
Tämän ratkaisu ansiosta tietokannan rakenteessa ei tarvitse määritellä, mitä kaikkea tietoa profiiliin mahdollisesti voidaan tallentaa, mutta tiedot on tallettu kuitenkin erillisinä.
Ystävyyssuhteet
- Käyttäjä voi ystävystyä muiden palvelun käyttäjien kanssa.
Tietokannassa täytyy olla tieto siitä, ketkä käyttäjät ovat ystäviä keskenään. Tämä onnistuu luomalla uusi taulu ystävyyssuhteita varten:
CREATE TABLE Ystavat (
id INTEGER PRIMARY KEY,
kayttaja1_id REFERENCES Kayttajat,
kayttaja2_id REFERENCES Kayttajat
);
Tämä taulu viittaa kahdesti tauluun Kayttajat, koska ystävyyssuhde liittyy kahteen käyttäjään.
Valokuvien lisääminen
- Käyttäjä voi lähettää palveluun valokuvia ja valita yhden niistä profiilikuvaksi.
Valokuvien lisääminen voidaan toteuttaa samaan tapaan kuin päivitysten lisääminen:
CREATE TABLE Valokuvat (
id INTEGER PRIMARY KEY,
kayttaja_id INTEGER REFERENCES Kayttajat,
kuva DATA
);
Tässä ei oteta tarkemmin kantaa siihen, miten valokuva tallennetaan palvelimelle, vaan sarakkeen tyyppinä on vain DATA.
Entä kuinka toteutamme profiilikuvan valitsemisen? Tähän on monia mahdollisia tapoja: voisimme lisätä tiedon asiasta tauluun Kayttajat tai Valokuvat tai luoda uuden taulun, joka kertoo, mikä kuva on kenenkin käyttäjän profiilikuva.
Koska käyttäjällä on enintään yksi profiilikuva, uudelle taululle ei ole oikeastaan tarvetta. Päädymme lisäämään tiedon tauluun Kayttajat, koska jos tieto olisi taulussa Valokuvat, pitäisi jotenkin erikseen varmistaa, että usea kuva ei ole samaan aikaan profiilikuvana. Tämän seurauksena taulu Kayttajat muuttuu näin:
CREATE TABLE Kayttajat (
id INTEGER PRIMARY KEY,
tunnus TEXT,
salasana TEXT,
kuva_id INTEGER REFERENCES Valokuvat
);
Tykkäykset ja kommentit
- Käyttäjät voivat tykätä ja kommentoida toistensa päivityksiä ja kuvia.
Tämän toiminnon toteuttamiseen on monia mahdollisuuksia. Seuraavassa ratkaisussa taulu Tykkaykset sisältää kaikki tykkäykset ja taulu Kommentit sisältää kaikki kommentit.
CREATE TABLE Tykkaykset (
id INTEGER PRIMARY KEY,
kayttaja_id INTEGER REFERENCES Kayttajat,
paivitys_id INTEGER REFERENCES Paivitykset,
kuva_id INTEGER REFERENCES Valokuvat
);
CREATE TABLE Kommentit (
id INTEGER PRIMARY KEY,
kayttaja_id INTEGER REFERENCES Kayttajat,
paivitys_id INTEGER REFERENCES Paivitykset,
kuva_id INTEGER REFERENCES Valokuvat,
viesti TEXT
aika DATETIME
);
Ideana on, että jos tykkäys tai kommentti liittyy päivitykseen, niin sarake paivitys_id osoittaa päivitykseen ja sarake kuva_id on NULL. Vastaavasti jos tykkäys tai kommentti liittyy kuvaan, sarake paivitys_id on NULL ja sarake kuva_id osoittaa kuvaan.
Vaihtoehtoinen ratkaisu olisi luoda kahden taulun sijasta neljä taulua niin, että päivitysten ja kuvien tiedot ovat omissa tauluissaan. Tämän etuna olisi, että riveillä ei ole NULL-arvoja, mutta tämä toisaalta mutkistaisi tietokannan rakennetta.
Yksityisviestit
- Käyttäjät voivat lähettää toisilleen yksityisviestejä.
Tämän toiminnon saamme toteutettua samalla tavalla kuin ystävystymisen lisäämällä uuden taulun, joka viittaa kahteen käyttäjään.
CREATE TABLE Viestit (
id INTEGER PRIMARY KEY,
kayttaja1_id INTEGER REFERENCES Kayttajat,
kayttaja2_id INTEGER REFERENCES Kayttajat,
viesti TEXT,
aika DATETIME
);
Tässä tulkintana on, että käyttäjä 1 on viestin lähettäjä ja käyttäjä 2 on viestin vastaanottaja.
Ylläpitäjät
- Palvelussa on myös ylläpitäjiä, joilla on enemmän oikeuksia kuin muilla käyttäjillä.
Tämän toiminnon toteuttamiseen on periaatteessa kaksi vaihtoehtoa: kaikki käyttäjät (myös ylläpitäjät) ovat samassa taulussa tai ylläpitäjät ovat erillisessä taulussa.
Kokemus on osoittanut, että parempi ratkaisu on tallentaa kaikki käyttäjät samaan tauluun, koska käyttäjillä on kuitenkin yhteisiä toimintoja, joiden toteuttaminen olisi hankalaa, jos tietoa pitäisi etsiä eri tauluista riippuen käyttäjän asemasta. Käyttäjät voidaan tallentaa samaan tauluun, kun tauluun lisätään sarake, joka ilmaisee käyttäjän roolin.
CREATE TABLE Kayttajat (
id INTEGER PRIMARY KEY,
tunnus TEXT,
salasana TEXT,
kuva_id INTEGER REFERENCES Valokuvat,
yllapitaja BOOLEAN
);
Tietokannan kuvaaminen
Tietokannan rakenteen kuvaamiseen on kaksi tavallista tapaa: graafinen tietokantakaavio, joka esittää taulujen suhteet, sekä SQL-skeema, jossa on taulujen luontikomennot.
Tietokantakaavio
Tietokantakaavio on tietokannan graafinen esitys, jossa jokainen tietokannan taulu on laatikko, joka sisältää taulun nimen ja sarakkeet listana. Rivien viittaukset toisiinsa esitetään laatikoiden välisinä yhteyksinä.
Tietokantakaavion piirtämiseen on monia vähän erilaisia tapoja. Seuraava kaavio on luotu netissä olevalla työkalulla dbdiagram.io:
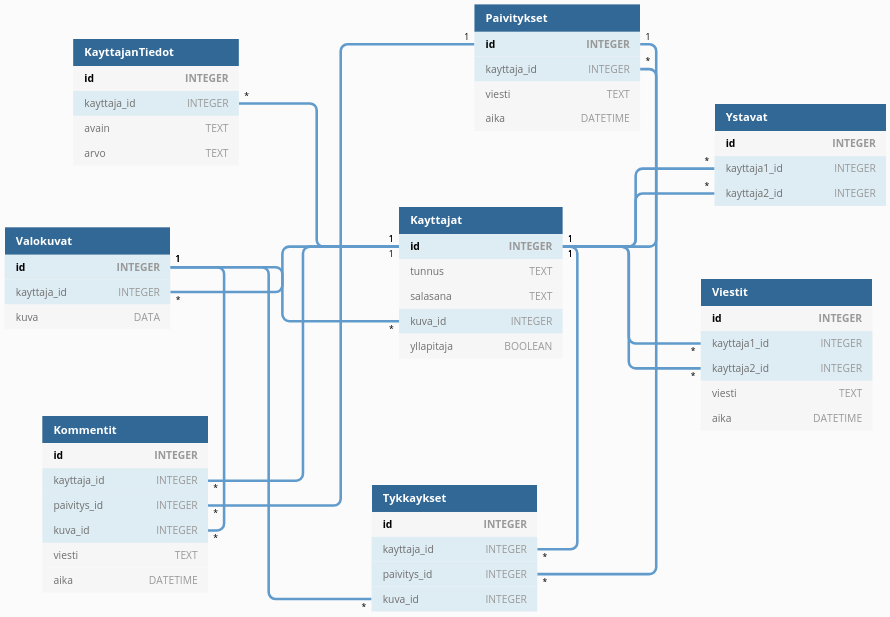
Tässä merkki 1 tarkoittaa, että sarakkeessa on eri arvo joka rivillä, ja merkki * puolestaan tarkoittaa, että sarakkeessa voi olla sama arvo usealla rivillä.
SQL-skeema
SQL-skeema sisältää CREATE TABLE -komennot, joiden avulla tietokanta voidaan muodostaa. Seuraava SQL-skeema vastaa tietokantaamme:
CREATE TABLE Kayttajat (
id INTEGER PRIMARY KEY,
tunnus TEXT,
salasana TEXT,
kuva_id INTEGER REFERENCES Valokuvat,
yllapitaja BOOLEAN
);
CREATE TABLE Paivitykset (
id INTEGER PRIMARY KEY,
kayttaja_id INTEGER REFERENCES Kayttajat,
viesti TEXT,
aika DATETIME
);
CREATE TABLE KayttajanTiedot (
id INTEGER PRIMARY KEY,
kayttaja_id INTEGER REFERENCES Kayttajat,
avain TEXT,
arvo TEXT
);
CREATE TABLE Ystavat (
id INTEGER PRIMARY KEY,
kayttaja1_id REFERENCES Kayttajat,
kayttaja2_id REFERENCES Kayttajat
);
CREATE TABLE Valokuvat (
id INTEGER PRIMARY KEY,
kayttaja_id INTEGER REFERENCES Kayttajat,
kuva DATA
);
CREATE TABLE Tykkaykset (
id INTEGER PRIMARY KEY,
kayttaja_id INTEGER REFERENCES Kayttajat,
paivitys_id INTEGER REFERENCES Paivitykset,
kuva_id INTEGER REFERENCES Valokuvat
);
CREATE TABLE Kommentit (
id INTEGER PRIMARY KEY,
kayttaja_id INTEGER REFERENCES Kayttajat,
paivitys_id INTEGER REFERENCES Paivitykset,
kuva_id INTEGER REFERENCES Valokuvat,
viesti TEXT
aika DATETIME
);
CREATE TABLE Viestit (
id INTEGER PRIMARY KEY,
kayttaja1_id INTEGER REFERENCES Kayttajat,
kayttaja2_id INTEGER REFERENCES Kayttajat,
viesti TEXT,
aika DATETIME
);