1. Johdanto
Mikä on tietokanta
Tietokanta (database) on tietokoneella oleva kokoelma tietoa, johon voidaan suorittaa hakuja ja jonka sisältöä voidaan muuttaa. Tietokantoja ovat esimerkiksi:
- nettisivuston käyttäjärekisteri
- verkkokaupan tuotteet ja varastotilanne
- pankin tiedot asiakkaista ja tilitapahtumista
- päivittäin mitatut säätiedot eri paikoissa
- lentoyhtiön lentoaikataulut ja varaustilanne
Tietokantoja on nykyään valtavasti, ja useimmat ihmiset ovat tavallisen päivän aikana yhteydessä lukuisiin tietokantoihin.
Tietokantojen haasteet
Tietokantojen tekniseen toteutukseen liittyy monia haasteita, eikä hyvin toimivan tietokannan toteuttaminen ole helppo tehtävä. Keskeisiä haasteita ovat:
Tiedon määrä
Monessa tietokannassa on suuri määrä tietoa, johon kohdistuu jatkuvasti hakuja ja muutoksia. Miten toteuttaa tietokanta niin, että tietoon pääsee käsiksi tehokkaasti?
Samanaikaisuus
Tietokannalla on yleensä useita käyttäjiä, jotka voivat hakea ja muuttaa tietoa samaan aikaan. Mitä tietokannan toteutuksessa tulee ottaa huomioon tähän liittyen?
Yllätykset
Tietokannan sisällön tulisi säilyä järkevänä myös yllättävissä tilanteissa. Esimerkiksi mitä tapahtuu, jos sähköt katkeavat juuri silloin, kun tietoa ollaan muuttamassa?
Tietokantajärjestelmät
Tietokantajärjestelmä pitää huolta tietokannan sisällöstä ja tarjoaa tietokannan käyttäjälle toiminnot, joiden avulla tietoa pystyy hakemaan ja muuttamaan. Huomaa, että termiä tietokanta käytetään usein myös silloin, kun viitataan tietokantajärjestelmään.
Useimmat käytössä olevat tietokannat perustuvat relaatiomalliin ja SQL-kieleen, joihin tutustumme tällä kurssilla. Esimerkiksi MySQL, PostgreSQL ja SQLite ovat tällaisia tietokantajärjestelmiä. Näiden tietokantojen teoreettinen perusta syntyi 1970-luvulla.
Termi NoSQL viittaa tietokantaan, joka perustuu muuhun kuin relaatiomalliin ja SQL-kieleen. Esimerkiksi MongoDB ja Redis ovat saavuttaneet viime aikoina suosiota. Tällä kurssilla emme kuitenkaan juurikaan käsittele NoSQL-tietokantoja.
Tee-se-itse-tietokanta
Ennen tutustumista olemassa oleviin tietokantajärjestelmiin on hyvä miettiä, mitä tarvetta tällaisille järjestelmille on. Miksi emme voisi vain toteuttaa tietokantaa itse vaikkapa tallentamalla tietokannan sisällön tekstitiedostoon sopivassa muodossa?
Esimerkki
Haluamme tallentaa tietokantaan tietoa kurssin opiskelijoiden ratkaisuista kurssin tehtäviin. Kun opiskelija lähettää ratkaisun, tietokantaan tallennetaan opiskelijanumero, tehtävän numero, ratkaisun lähetysaika sekä ratkaisun tuottama pistemäärä.
Yksinkertainen tapa toteuttaa tietokanta on luoda yksi tekstitiedosto, jonka jokaisella rivillä on yksi lähetys. Aina kun joku opiskelija lähettää ratkaisun, tiedostoon lisätään yksi rivi. Voisimme käytännössä tallentaa tietokannan CSV-tiedostona tähän tapaan:
012121212;1;2020-05-03 12:50:32;100
012341234;1;2020-05-03 14:02:12;100
012121212;2;2020-05-04 14:05:50;100
012121212;3;2020-05-04 14:43:12;0
012341234;2;2020-05-04 10:15:23;0
012341234;2;2020-05-04 16:40:39;0
013371337;1;2020-05-06 18:11:13;0
012341234;2;2020-05-07 10:02:15;100
CSV-tiedostossa tietty erotinmerkki erottaa riveillä olevat kentät. Tässä tapauksessa erotinmerkkinä on puolipiste ;. Esimerkiksi tiedoston ensimmäinen rivi kertoo, että opiskelija 012121212 on lähettänyt ratkaisun tehtävään 1 ja saanut siitä 100 pistettä.
Nyt jos haluamme vaikkapa selvittää jokaisen opiskelijan lähetysten määrän, voimme hoitaa asian näin Python-kielellä:
count = {}
for line in open("lahetykset.csv"):
parts = line.split(";")
if parts[0] not in count:
count[parts[0]] = 0
count[parts[0]] += 1
print(count)
Ohjelma antaa seuraavan tuloksen:
{'012121212': 3, '012341234': 4, '013371337': 1}
Tämä tarkoittaa, että opiskelija 012121212 on lähettänyt kolme ratkaisua, opiskelija 012341234 on lähettänyt neljä ratkaisua ja opiskelija 013371337 on lähettänyt yhden ratkaisun.
Mahdolliset ongelmat
Tällainen CSV-tiedostoa käyttävä tietokanta on periaatteessa toimiva, mutta sen käyttäminen voi johtaa ongelmiin:
Tiedon määrä
Kun tiedon määrä kasvaa, tiedon hakeminen CSV-tiedostosta voi muodostua ongelmaksi. Tämä johtuu siitä, että joudumme useimmissa tilanteissa käymään läpi koko tiedoston sisällön alusta loppuun, kun haluamme saada haettua tietyn asian.
Esimerkiksi jos haluamme selvittää, minkä pistemäärän opiskelija 012341234 on saanut tehtävästä 2, joudumme käymään läpi tiedoston kaikki rivit, jotta löydämme oikeat rivit. Joudumme tekemään näin, koska rivit ovat sekalaisessa järjestyksessä eikä meillä ole etukäteen tietoa, missä haluamamme rivit ovat.
Tiedoston läpikäynti ei ole ongelma, jos tiedosto on pieni. Esimerkiksi jos tiedostossa on sata riviä, läpikäynti sujuu hyvin nopeasti. Mutta tiedoston koon kasvaessa alkaa olla työlästä käydä kaikki rivit läpi aina, kun haluamme saada selville jotain tiedostosta.
Samanaikaisuus
Mitä tapahtuu, jos kaksi opiskelijaa lähettävät ratkaisun samaan aikaan? Tällöin tiedoston loppuun pitäisi tulla kaksi riviä tietoa seuraavaan tapaan:
012341234;3;2020-05-07 15:42:02;0
013371337;7;2020-05-07 15:42:02;0
Jos käy huonosti, voi kuitenkin käydä näin:
012341234;3;2020013371337;7;2020-05-07 15:42:02;0
-05-07 15:42:02;0
Tässä ensimmäinen prosessi kirjoittaa ensin tiedoston loppuun 012341234;3;2020, sitten toinen prosessi kirjoittaa väliin 013371337;7;2020-05-07 15:42:02;0 ja lopuksi ensimmäinen prosessi kirjoittaa -05-07 15:42:02;0. Tämän seurauksena tiedoston rakenne menee sekaisin.
Kun tiedostoon kirjoitetaan tietoa, ei ole itsestään selvää, että tieto menee perille yhtenäisenä, jos joku muu koettaa kirjoittaa samaan aikaan. Tämä riippuu tiedostojärjestelmästä, tiedon määrästä ja tiedoston käsittelytavasta.
Yllätykset
Tarkastellaan tilannetta, jossa haluamme poistaa tietokannasta opiskelijan 012341234 lähetykset. Voimme tehdä tämän lukemalla ensin kaikki rivit muistiin ja kirjoittamalla sitten takaisin tiedostoon kaikki rivit, joissa opiskelija ei ole 012341234.
Mitä jos sähköt katkeavat juuri, kun olemme kirjoittaneet puolet riveistä takaisin? Kun käynnistämme tietokannan uudestaan, huomaamme, että tiedostossa on vain puolet riveistä ja loput ovat kadonneet eikä meillä ole keinoa saada niitä takaisin.
Mitä opimme tästä?
Yksinkertainen tekstitiedosto ei ole sinänsä huono tapa tallentaa tietoa, mutta se ei sovellu kaikkiin käyttötarkoituksiin. Tämän vuoksi tarvitsemme erillisiä tietokantajärjestelmiä, joihin tutustumme tällä kurssilla.
Tietokantajärjestelmien kehittäjät ovat miettineet tarkasti, miten järjestelmä kannattaa toteuttaa, jotta tietoon pääsee käsiksi tehokkaasti, samanaikaiset käyttäjät eivät aiheuta ongelmia eikä tietoa katoa yllättävissä tilanteissa. Kun käytämme tietokantajärjestelmää, meidän ei tarvitse huolehtia tästä kaikesta itse.
Relaatiomalli ja SQL-kieli
Tällä kurssilla tutustumme tietokantoihin relaatiomallin ja SQL-kielen kautta. Relaatiomallin ytimessä on kaksi perusideaa:
- Kaikki tieto tallennetaan tauluihin riveinä, jotka voivat viitata toisiinsa.
- Tietokannan käyttäjä käsittelee tietoa SQL-kielellä, joka kätkee käyttäjältä tietokannan sisäisen toiminnan yksityiskohdat.
Tietokannan rakenne
Relaatiomallissa tietokanta muodostuu tauluista (table), joissa on kiinteät sarakkeet (column). Tauluihin tallennetaan tietoa riveinä (row), joilla on tietyt arvot sarakkeissa. Jokaisessa taulussa on kokoelma tiettyyn asiaan liittyvää tietoa.
Seuraavassa kuvassa on esimerkki tietokannasta, jota voisi käyttää osana verkkokaupan toteutusta. Tauluissa Tuotteet, Asiakkaat ja Ostokset on tietoa tuotteista, asiakkaista ja heidän ostoskoriensa sisällöstä.
| Tuotteet | ||
|---|---|---|
| id | nimi | hinta |
| 1 | retiisi | 7 |
| 2 | porkkana | 5 |
| 3 | nauris | 4 |
| 4 | lanttu | 8 |
| 5 | selleri | 4 |
| Asiakkaat | |
|---|---|
| id | nimi |
| 1 | Uolevi |
| 2 | Maija |
| 3 | Aapeli |
| Ostokset | |
|---|---|
| asiakas_id | tuote_id |
| 1 | 2 |
| 1 | 5 |
| 2 | 1 |
| 2 | 4 |
| 2 | 5 |
Tauluissa Tuotteet ja Asiakkaat jokaisella rivillä on yksilöllinen id-numero, jonka avulla niihin voi viitata. Tämä on yleinen tapa tietokantojen suunnittelussa. Tämän ansiosta taulussa Ostokset voidaan esittää id-numeroiden avulla, mitä tuotteita kukin asiakas on valinnut. Tässä esimerkissä Uolevin korissa on porkkana ja selleri ja Maijan korissa on retiisi, lanttu ja selleri.
SQL-kieli
SQL (Structured Query Language) on vakiintunut tapa käsitellä tietokannan sisältöä. Kielessä on komentoja, joiden avulla tietokannan käyttäjä (esimerkiksi tietokantaa käyttävä ohjelmoija) voi lisätä, hakea, muuttaa ja poistaa tietoa.
SQL-komennot muodostuvat avainsanoista (kuten SELECT ja WHERE), taulujen ja sarakkeiden nimistä sekä muista arvoista. Esimerkiksi komento
SELECT hinta FROM Tuotteet WHERE nimi='retiisi';
hakee tietokannan tuotteista retiisin hinnan. Komentojen lopussa on puolipiste ; ja voimme käyttää välilyöntejä ja rivinvaihtoja haluamallamme tavalla. Esimerkiksi voisimme kirjoittaa äskeisen komennon myös näin usealle riville:
SELECT
hinta
FROM
Tuotteet
WHERE
nimi='retiisi';
Tutustumme SQL-kieleen tarkemmin materiaalin luvuissa 2–4.
SQL-kieli syntyi 1970-luvulla, ja siinä on paljon muistumia vanhan ajan ohjelmoinnista. Tällaisia piirteitä ovat esimerkiksi:
- Avainsanat ovat kokonaisia englannin kielen sanoja, ja komennot muistuttavat englannin kielen lauseita.
- Avainsanoissa kirjainkoolla ei ole väliä. Esimerkiksi
SELECT,selectjaSelecttarkoittavat samaa. Avainsanat on tapana kirjoittaa kokonaan suurilla kirjaimilla. - Merkki
=tarkoittaa sekä asetusta että yhtäsuuruusvertailua (nykyään ohjelmoinnissa yhtäsuuruusvertailu on yleensä==).
SQL-kielestä on olemassa standardeja, jotka pyrkivät antamaan yhteisen pohjan kielelle. Käytännössä jokainen SQL-kielen toteutus toimii kuitenkin hieman omalla tavallaan. Tällä kurssilla keskitymme SQL:n ominaisuuksiin, jotka ovat yleisesti käytettävissä eri tietokannoissa.
Tietokannan sisäinen toiminta
Tietokantajärjestelmän tehtävänä on käsitellä käyttäjän antamat SQL-komennot. Esimerkiksi kun käyttäjä antaa komennon, joka hakee tietoa tietokannasta, tietokantajärjestelmän tulee löytää jokin hyvä tapa käsitellä komento ja toimittaa tulokset takaisin käyttäjälle mahdollisimman nopeasti.
SQL-kielen hienoutena on, että käyttäjän riittää kuvailla, mitä tietoa hän haluaa, minkä jälkeen tietokantajärjestelmä hoitaa likaisen työn ja hankkii tiedot tietokannan uumenista. Tämä on mukavaa käyttäjälle, koska hänen ei tarvitse tietää mitään tietokannan sisäisestä toiminnasta vaan voi luottaa tietokantajärjestelmään.
Tietokantajärjestelmän toteuttaminen on vaikea tehtävä, koska järjestelmän täytyy sekä osata käsitellä tehokkaasti SQL-komentoja että huolehtia siitä, että kaikki toimii oikein samanaikaisilla käyttäjillä ja yllättävissä tilanteissa. Tällä kurssilla tutustumme tietokantoihin lähinnä tietokannan käyttäjän näkökulmasta emmekä perehdy niiden sisäiseen toimintaan.
2. SQL-kielen perusteet
Peruskomennot
Tässä luvussa tutustumme tavallisimpiin SQL-komentoihin, joiden avulla voimme lisätä, hakea, muuttaa ja poistaa tietokannan sisältöä. Nämä komennot muodostavat perustan tietokannan käyttämiselle.
Taulun luonti
Komento CREATE TABLE luo taulun, jossa on halutut sarakkeet. Esimerkiksi seuraava komento luo taulun Tuotteet, jossa on kolme saraketta:
CREATE TABLE Tuotteet (id INTEGER PRIMARY KEY, nimi TEXT, hinta INTEGER);
Voimme nimetä taulun ja sarakkeet haluamallamme tavalla. Tällä kurssilla käytäntönä on, että kirjoitamme taulun nimen suurella alkukirjaimella ja monikkomuotoisena. Sarakkeiden nimet puolestaan kirjoitamme pienellä alkukirjaimella.
Jokaisesta sarakkeesta ilmoitetaan nimen lisäksi tyyppi. Tässä taulussa sarakkeet id ja hinta ovat kokonaislukuja (INTEGER) ja sarake nimi on merkkijono (TEXT). Sarake id on lisäksi taulun pääavain (PRIMARY KEY), mikä tarkoittaa, että se yksilöi jokaisen taulun rivin ja voimme viitata sen avulla kätevästi mihin tahansa riviin.
Pääavain
Tietokannan taulun pääavain on jokin sarake (tai sarakkeiden yhdistelmä), joka yksilöi taulun jokaisen rivin eli millään kahdella rivillä ei ole samaa pääavainta. Käytännössä hyvin tavallinen valinta pääavaimeksi on kokonaislukumuotoinen id-numero.
Usein haluamme lisäksi, että id-numerolla on juokseva numerointi. Tämä tarkoittaa, että kun tauluun lisätään rivejä, ensimmäinen rivi saa automaattisesti id-numeron 1, toinen rivi saa id-numeron 2, jne. Juoksevan numeroinnin toteuttaminen riippuu tietokantajärjestelmästä. Esimerkiksi SQLite-tietokannassa INTEGER PRIMARY KEY -tyyppinen sarake saa automaattisesti juoksevan numeroinnin.
Tiedon lisääminen
Komento INSERT lisää uuden rivin tauluun. Esimerkiksi seuraava komento lisää rivin äsken luomaamme tauluun Tuotteet:
INSERT INTO Tuotteet (nimi,hinta) VALUES ('retiisi',7);
Tässä annamme arvot lisättävän rivin sarakkeille nimi ja hinta. Kun sarakkeessa id on juokseva numerointi, se saa automaattisesti arvon 1, kun kyseessä on taulun ensimmäinen rivi. Niinpä tauluun ilmestyy seuraava rivi:
id nimi hinta
---------- ---------- ----------
1 retiisi 7
Jos emme anna arvoa jollekin sarakkeelle, se saa oletusarvon. Tavallisessa sarakkeessa oletusarvo on NULL, mikä tarkoittaa tiedon puuttumista. Esimerkiksi seuraavassa komennossa emme anna arvoa sarakkeelle hinta:
INSERT INTO Tuotteet (nimi) VALUES ('retiisi');
Tällöin tauluun ilmestyy rivi, jossa hinta on NULL (eli tyhjä):
id nimi hinta
---------- ---------- ----------
1 retiisi
Esimerkkitaulu
Oletamme tämän osion tulevissa esimerkeissä, että olemme lisänneet tauluun Tuotteet seuraavat viisi riviä:
INSERT INTO Tuotteet (nimi,hinta) VALUES ('retiisi',7);
INSERT INTO Tuotteet (nimi,hinta) VALUES ('porkkana',5);
INSERT INTO Tuotteet (nimi,hinta) VALUES ('nauris',4);
INSERT INTO Tuotteet (nimi,hinta) VALUES ('lanttu',8);
INSERT INTO Tuotteet (nimi,hinta) VALUES ('selleri',4);
Taulun sisältö on siis seuraavanlainen:
id nimi hinta
---------- ---------- ----------
1 retiisi 7
2 porkkana 5
3 nauris 4
4 lanttu 8
5 selleri 4
Tiedon hakeminen
Komento SELECT suorittaa kyselyn eli hakee tietoa taulusta. Yksinkertaisin tapa tehdä kysely on hakea kaikki tiedot taulusta:
SELECT * FROM Tuotteet;
Tässä tapauksessa kyselyn tulos on seuraava:
id nimi hinta
---------- ---------- ----------
1 retiisi 7
2 porkkana 5
3 nauris 4
4 lanttu 8
5 selleri 4
Kyselyssä tähti * ilmaisee, että haluamme hakea kaikki sarakkeet. Kuitenkin voimme myös hakea vain osan sarakkeista. Esimerkiksi seuraava kysely hakee vain tuotteiden nimet:
SELECT nimi FROM Tuotteet;
Kyselyn tulos on seuraava:
nimi
----------
retiisi
porkkana
nauris
lanttu
selleri
Tämä kysely puolestaan hakee nimet ja hinnat:
SELECT nimi, hinta FROM Tuotteet;
Nyt kyselyn tulos muuttuu näin:
nimi hinta
---------- ----------
retiisi 7
porkkana 5
nauris 4
lanttu 8
selleri 4
Kyselyn tuloksena olevat rivit muodostavat taulun, jota kutsutaan nimellä tulostaulu. Sen sarakkeet ja rivit riippuvat kyselyn sisällöstä. Esimerkiksi äskeinen kysely loi tulostaulun, jossa on kaksi saraketta ja viisi riviä.
Tietokannan käsittelyssä esiintyy siis kahdenlaisia tauluja: tietokannassa kiinteästi olevia tauluja, joihin on tallennettu tietokannan sisältö, sekä kyselyjen muodostamia väliaikaisia tulostauluja, joiden tiedot on koostettu kiinteistä tauluista.
Hakuehto
Liittämällä SELECT-kyselyyn WHERE-osan voimme valita vain osan riveistä halutun ehdon perusteella. Esimerkiksi seuraava kysely hakee tiedot lantusta:
SELECT * FROM Tuotteet WHERE nimi='lanttu';
Kyselyn tulos on seuraava:
id nimi hinta
---------- ---------- ----------
4 lanttu 8
Ehdoissa voi käyttää vertailuja ja sanoja AND ja OR samaan tapaan kuin ohjelmoinnissa. Esimerkiksi seuraava kysely etsii tuotteet, joiden hinta on välillä 4…6:
SELECT * FROM Tuotteet WHERE hinta>=4 AND hinta<=6;
Kyselyn tulos on seuraava:
id nimi hinta
---------- ---------- ----------
2 porkkana 5
3 nauris 4
5 selleri 4
Järjestäminen
Oletuksena kyselyn tuloksena olevien rivien järjestys voi olla mikä tahansa. Voimme kuitenkin määrittää halutun järjestyksen ORDER BY -osan avulla. Esimerkiksi seuraava kysely hakee tuotteet järjestyksessä nimen mukaan:
SELECT * FROM Tuotteet ORDER BY nimi;
Kyselyn tulos on seuraava:
id nimi hinta
---------- ---------- ----------
4 lanttu 8
3 nauris 4
2 porkkana 5
1 retiisi 7
5 selleri 4
Järjestys on oletuksena pienimmästä suurimpaan. Kuitenkin jos haluamme järjestyksen suurimmasta pienimpään, voimme lisätä sanan DESC sarakkeen nimen jälkeen:
SELECT * FROM Tuotteet ORDER BY nimi DESC;
Tämän seurauksena kyselyn tulos on seuraava:
id nimi hinta
---------- ---------- ----------
5 selleri 4
1 retiisi 7
2 porkkana 5
3 nauris 4
4 lanttu 8
Tietokantakielessä järjestys on joko nouseva (ascending) eli pienimmästä suurimpaan tai laskeva (descending) eli suurimmasta pienimpään. Oletuksena järjestys on nouseva, ja avainsana DESC tarkoittaa siis laskevaa järjestystä.
SQL-kielessä on myös avainsana ASC, joka tarkoittaa nousevaa järjestystä. Seuraavat kyselyt toimivat siis samalla tavalla:
SELECT * FROM Tuotteet ORDER BY nimi;
SELECT * FROM Tuotteet ORDER BY nimi ASC;
Käytännössä sanaa ASC käytetään kuitenkin äärimmäisen harvoin.
Voimme myös järjestää rivejä usealla eri perusteella. Esimerkiksi seuraava kysely järjestää rivit ensisijaisesti kalleimmasta halvimpaan hinnan mukaan ja toissijaisesti aakkosjärjestykseen nimen mukaan:
SELECT * FROM Tuotteet ORDER BY hinta DESC, nimi;
Kyselyn tulos on seuraava:
id nimi hinta
---------- ---------- ----------
4 lanttu 8
1 retiisi 7
2 porkkana 5
3 nauris 4
5 selleri 4
Tässä tapauksessa nauris ja selleri järjestetään nimen mukaan, koska ne ovat yhtä kalliita.
Erilliset tulosrivit
Joskus tulostaulussa voi olla useita samanlaisia rivejä. Näin käy esimerkiksi seuraavassa kyselyssä:
SELECT hinta FROM Tuotteet;
Koska kahden tuotteen hinta on 4, kahden tulosrivin sisältönä on 4:
hinta
----------
7
5
4
8
4
Jos kuitenkin haluamme vain erilaiset tulosrivit, voimme lisätä kyselyyn sanan DISTINCT:
SELECT DISTINCT hinta FROM Tuotteet;
Tämän seurauksena kyselyn tulos muuttuu näin:
hinta
----------
7
5
4
8
Tiedon muuttaminen
Komento UPDATE muuttaa taulun rivejä, jotka täsmäävät haluttuun ehtoon. Esimerkiksi seuraava komento muuttaa tuotteen 2 hinnaksi 6:
UPDATE Tuotteet SET hinta=6 WHERE id=2;
Useita sarakkeita voi muuttaa yhdistämällä muutokset pilkuilla. Esimerkiksi seuraava komento muuttaa tuotteen 2 nimeksi ananas ja hinnaksi 9:
UPDATE Tuotteet SET nimi='ananas', hinta=9 WHERE id=2;
Muutos voidaan myös laskea aiemman arvon perusteella. Esimerkiksi seuraava komento kasvattaa tuotteen 2 hintaa yhdellä:
UPDATE Tuotteet SET hinta=hinta+1 WHERE id=2;
Jos komennossa ei ole ehtoa, se vaikuttaa kaikkiin riveihin. Esimerkiksi seuraava komento kasvattaa jokaisen tuotteen hintaa yhdellä:
UPDATE Tuotteet SET hinta=hinta+1;
Tiedon poistaminen
Komento DELETE poistaa taulusta rivit, jotka täsmäävät annettuun ehtoon. Esimerkiksi seuraava komento poistaa taulusta tuotteen 5:
DELETE FROM Tuotteet WHERE id=5;
Kuten muuttamisessa, jos ehtoa ei ole, niin komento vaikuttaa kaikkiin riveihin. Seuraava komento siis poistaa kaikki tuotteet taulusta:
DELETE FROM Tuotteet;
Komento DROP TABLE poistaa tietokannan taulun (ja kaiken sen sisällön). Esimerkiksi seuraava komento poistaa taulun Tuotteet:
DROP TABLE Tuotteet;
Yhteenveto ja ryhmittely
Yhteenvetokysely laskee jonkin yksittäisen arvon taulun riveistä, kuten taulun rivien määrän tai sarakkeen kaikkien arvojen summan. Tällaisen kyselyn tulostaulussa on vain yksi rivi.
Yhteenvetokyselyn perustana on koostefunktio, joka laskee yhteenvetoarvon taulun riveistä. Tavallisimmat koostefunktiot ovat seuraavat:
COUNT()laskee rivien määränSUM()laskee summan arvoistaMIN()hakee pienimmän arvonMAX()hakee suurimman arvon
Esimerkkejä
Tarkastellaan taas taulua Tuotteet:
id nimi hinta
---------- ---------- ----------
1 retiisi 7
2 porkkana 5
3 nauris 4
4 lanttu 8
5 selleri 4
Seuraava kysely hakee taulun rivien määrän:
SELECT COUNT(*) FROM Tuotteet;
COUNT(*)
----------
5
Seuraava kysely hakee niiden rivien määrän, joissa hinta on 4:
SELECT COUNT(*) FROM Tuotteet WHERE hinta=4;
COUNT(*)
----------
2
Seuraava kysely puolestaan laskee summan tuotteiden hinnoista:
SELECT SUM(hinta) FROM Tuotteet;
SUM(hinta)
----------
28
Rivien valinta
Jos COUNT-funktion sisällä on tähti *, kysely laskee kaikki rivit. Jos taas funktion sisällä on sarakkeen nimi, kysely laskee rivit, joissa sarakkeessa on arvo (eli sarake ei ole NULL).
Tarkastellaan esimerkkinä seuraavaa taulua, jossa rivillä 3 ei ole hintaa:
id nimi hinta
---------- ---------- ----------
1 retiisi 7
2 nauris 4
3 lanttu
4 selleri 4
Seuraava kysely hakee rivien yhteismäärän:
SELECT COUNT(*) FROM Tuotteet;
COUNT(*)
----------
4
Seuraava kysely taas hakee niiden rivien määrän, joilla on hinta:
SELECT COUNT(hinta) FROM Tuotteet;
COUNT(hinta)
------------
3
Voimme myös käyttää sanaa DISTINCT, jotta saamme laskettua, montako eri arvoa jossakin sarakkeessa on:
SELECT COUNT(DISTINCT hinta) FROM Tuotteet;
COUNT(DISTINCT hinta)
---------------------
2
Ryhmittely
Ryhmittelyn avulla voimme yhdistää rivikohtaista ja koostefunktion antamaa tietoa. Ideana on, että rivit jaetaan ryhmiin GROUP BY -osassa annettujen sarakkeiden mukaan ja tämän jälkeen koostefunktion arvo lasketaan jokaiselle ryhmälle erikseen.
Esimerkki
Tarkastellaan esimerkkinä seuraavaa taulua Tyontekijat, jossa on työntekijöiden tietoja:
id nimi yritys palkka
---------- ---------- ---------- ----------
1 Anna Google 8000
2 Liisa Google 7500
3 Kaaleppi Amazon 5000
4 Uolevi Amazon 8000
5 Maija Google 9500
6 Vihtori Facebook 5000
Seuraava kysely hakee kunkin yrityksen työntekijöiden määrän:
SELECT yritys, COUNT(*) FROM Tyontekijat GROUP BY yritys;
Kyselyn tulos on seuraava:
yritys COUNT(*)
---------- ----------
Amazon 2
Facebook 1
Google 3
Tämä tarkoittaa, että Amazonilla on 2 työntekijää, Facebookilla on 1 työntekijä ja Googlella on 3 työntekijää.
Miten ryhmittely toimii?
Äskeisessä kyselyssä ryhmittelyn ehtona on GROUP BY yritys, joten rivit jaetaan ryhmiin sarakkeen yritys mukaan. Tässä tapauksessa ryhmät ovat:
id nimi yritys palkka
---------- ---------- ---------- ----------
3 Kaaleppi Amazon 5000
4 Uolevi Amazon 8000
id nimi yritys palkka
---------- ---------- ---------- ----------
6 Vihtori Facebook 5000
id nimi yritys palkka
---------- ---------- ---------- ----------
1 Anna Google 8000
2 Liisa Google 7500
5 Maija Google 9500
Tämän jälkeen jokaiselle ryhmälle lasketaan rivien määrä koostefunktion COUNT(*) avulla.
Ryhmittely tuottaa tulostaulun, jonka rivien määrä on sama kuin ryhmien määrä. Jokaisella rivillä voi esiintyä ryhmittelyssä käytettyjä sarakkeita sekä koostefunktioita.
Huomaa, että SQLite sallii myös seuraavan kyselyn, jossa haetaan ryhmittelyn ulkopuolinen sarake:
SELECT yritys, nimi FROM Tyontekijat GROUP BY yritys;
yritys nimi
---------- ----------
Amazon Uolevi
Facebook Vihtori
Google Maija
Koska sarake nimi ei kuulu ryhmittelyyn, sillä voi olla useita arvoja ryhmässä ja tulostauluun tulee yksi niistä. Tällainen kysely ei kuitenkaan toimi kaikissa tietokannoissa.
Lisää kyselyjä
Seuraava kysely hakee joka yrityksestä palkkojen summan:
SELECT yritys, SUM(palkka) FROM Tyontekijat GROUP BY yritys;
yritys SUM(palkka)
---------- -----------
Amazon 13000
Facebook 5000
Google 25000
Seuraava kysely puolestaan hakee korkeimman palkan:
SELECT yritys, MAX(palkka) FROM Tyontekijat GROUP BY yritys;
yritys MAX(palkka)
---------- -----------
Amazon 8000
Facebook 5000
Google 9500
Tulossarakkeen nimentä
Oletuksena tulostaulun sarake saa nimen suoraan kyselyn perusteella, mutta voimme halutessamme antaa myös oman nimen AS-sanan avulla. Tämän ansiosta voimme esimerkiksi selventää,
mistä yhteenvetokyselyssä on kyse.
Esimerkiksi seuraavassa kyselyssä toisen sarakkeen nimeksi tulee korkein:
SELECT yritys, MAX(palkka) AS korkein FROM Tyontekijat GROUP BY yritys;
yritys korkein
---------- ----------
Amazon 8000
Facebook 5000
Google 9500
Sana AS ei ole pakollinen, eli voisimme kirjoittaa kyselyn myös näin:
SELECT yritys, MAX(palkka) korkein FROM Tyontekijat GROUP BY yritys;
Rajaus ryhmittelyn jälkeen
Voimme lisätä kyselyyn myös HAVING-osan, joka rajaa tuloksia ryhmittelyn jälkeen. Esimerkiksi seuraava kysely hakee yritykset, joissa on ainakin kaksi työntekijää:
SELECT yritys, COUNT(*) FROM Tyontekijat GROUP BY yritys HAVING COUNT(*) >= 2;
yritys COUNT(*)
---------- ----------
Amazon 2
Google 3
Voimme myös käyttää koostefunktiota vain HAVING-osassa:
SELECT yritys FROM Tyontekijat GROUP BY yritys HAVING COUNT(*) >= 2;
yritys
----------
Amazon
Google
Kyselyn yleiskuva
SQL-kyselyn yleiskuva on seuraava:
SELECT – FROM – WHERE – GROUP BY – HAVING – ORDER BY
Kyselystä riippuu, mitkä näistä osista siinä esiintyvät. Tämä on kuitenkin aina järjestys, jossa kyselyn osat sijaitsevat toisiinsa nähden.
Seuraavassa on esimerkki kyselystä, joka sisältää yhtä aikaa kaikki nämä osat.
Esimerkki
Tarkastellaan taulua Tehtavat, jossa on projekteihin liittyviä tehtäviä. Jokaisella tehtävällä on tietty tärkeysaste. Tehtävä on kriittinen, jos sen tärkeysaste on ainakin 3.
id projekti_id tarkeys
---------- ----------- ----------
1 1 3
2 1 4
3 1 4
4 2 1
5 2 5
6 3 2
7 3 4
8 3 5
Seuraava kysely etsii projektit, joissa on vähintään kaksi kriittistä tehtävää, ja järjestää ne projektin id-numeron mukaan:
SELECT
projekti_id, COUNT(*)
FROM
Tehtavat
WHERE
tarkeys >= 3
GROUP BY
projekti_id
HAVING
COUNT(*) >= 2
ORDER BY
projekti_id;
Kyselyn tulos on tässä:
projekti_id COUNT(*)
----------- ----------
1 3
3 2
Tämä tarkoittaa, että projektissa 1 on 3 kriittistä tehtävää ja projektissa 3 on 2 kriittistä tehtävää.
Miten kysely toimii?
Kyselyn lähtökohtana ovat kaikki taulussa Tehtavat olevat rivit. Ehto WHERE tarkeys >= 3 valitsee käsittelyyn seuraavat rivit:
id projekti_id tarkeys
---------- ----------- ----------
1 1 3
2 1 4
3 1 4
5 2 5
7 3 4
8 3 5
Kyselyssä on käytössä ryhmittely GROUP BY projekti_id, joka jakaa rivit ryhmiin näin:
id projekti_id tarkeys
---------- ----------- ----------
1 1 3
2 1 4
3 1 4
id projekti_id tarkeys
---------- ----------- ----------
5 2 5
id projekti_id tarkeys
---------- ----------- ----------
7 3 4
8 3 5
Osa HAVING COUNT(*) >= 2 valitsee ryhmät, joissa on ainakin kaksi riviä:
id projekti_id tarkeys
---------- ----------- ----------
1 1 3
2 1 4
3 1 4
id projekti_id tarkeys
---------- ----------- ----------
7 3 4
8 3 5
Tulostauluun valitaan joka ryhmästä sarake projekti_id sekä funktion COUNT(*) arvo, ja ORDER BY projekti_id järjestää rivit projektin id-numeron mukaan:
projekti_id COUNT(*)
----------- ----------
1 3
3 2
SQLite-tietokanta
SQLite on yksinkertainen avoimesti saatavilla oleva tietokantajärjestelmä, joka soveltuu hyvin SQL-kielen opetteluun. Voit kokeilla helposti SQL-kieleen liittyviä asioita SQLiten avulla, ja käytämme sitä tämän kurssin harjoituksissa.
SQLite on mainio valinta SQL-kielen harjoitteluun, mutta siinä on tiettyjä rajoituksia, jotka voivat aiheuttaa ongelmia todellisissa sovelluksissa. Muita suosittuja avoimia tietokantajärjestelmiä ovat MySQL ja PostgreSQL. Niissä on suuri määrä ominaisuuksia, jotka puuttuvat SQLitestä, mutta toisaalta niiden asentaminen ja käyttäminen on vaikeampaa.
Eri tietokantajärjestelmien välillä siirtyminen on onneksi helppoa, koska kaikissa on samantapainen SQL-kieli. Tutustumme PostgreSQL-tietokannan käyttämiseen myöhemmin Tietokantasovellus-kurssilla.
SQLite-tulkki
SQLite-tulkki on ohjelma, jonka kautta voidaan käyttää SQLite-tietokantaa. Tulkki käynnistyy antamalla komentorivillä komento sqlite3. Tämän jälkeen tulkkiin voi kirjoittaa joko suoritettavia SQL-komentoja tai pisteellä alkavia SQLite-tulkin omia komentoja.
Jos käyttämälläsi koneella ei ole vielä SQLite-tulkkia, voit asentaa sen tästä:
Valitse oman käyttöjärjestelmäsi mukainen paketti, jonka vieressä on otsikko command-line tools (eli komentorivityökalut). Tarvittava tiedosto on se, jonka nimi alkaa sqlite3.
Esimerkki
SQLite-tulkissa tietokanta on oletuksena muistissa (in-memory database), jolloin se on aluksi tyhjä ja katoaa, kun tulkki suljetaan. Tämä on hyvä tapa testailla SQL-kielen ominaisuuksia. Keskustelu tulkin kanssa voi näyttää vaikkapa tältä:
$ sqlite3
SQLite version 3.11.0 2016-02-15 17:29:24
Enter ".help" for usage hints.
Connected to a transient in-memory database.
Use ".open FILENAME" to reopen on a persistent database.
sqlite> CREATE TABLE Tuotteet (id INTEGER PRIMARY KEY, nimi TEXT, hinta INTEGER);
sqlite> .tables
Tuotteet
sqlite> INSERT INTO Tuotteet (nimi,hinta) VALUES ('retiisi',7);
sqlite> INSERT INTO Tuotteet (nimi,hinta) VALUES ('porkkana',5);
sqlite> INSERT INTO Tuotteet (nimi,hinta) VALUES ('nauris',4);
sqlite> INSERT INTO Tuotteet (nimi,hinta) VALUES ('lanttu',8);
sqlite> INSERT INTO Tuotteet (nimi,hinta) VALUES ('selleri',4);
sqlite> SELECT * FROM Tuotteet;
1|retiisi|7
2|porkkana|5
3|nauris|4
4|lanttu|8
5|selleri|4
sqlite> .mode column
sqlite> .headers on
sqlite> SELECT * FROM Tuotteet;
id nimi hinta
---------- ---------- ----------
1 retiisi 7
2 porkkana 5
3 nauris 4
4 lanttu 8
5 selleri 4
sqlite> .quit
Esimerkissä luomme aluksi taulun Tuotteet ja tarkastamme sitten komennolla .tables, mitä tauluja tietokannassa on. Ainoa taulu on Tuotteet, mikä kuuluu asiaan.
Tämän jälkeen lisäämme tauluun rivejä ja haemme sitten kaikki rivit taulusta. SQLite-tulkin oletustapa näyttää tulosrivit pystyviivoin erotettuina ei ole kovin tyylikäs, minkä vuoksi parannamme tulostusta komennoilla .mode column (jokaisella sarakkeella on kiinteä leveys) ja .headers on (sarakkeiden nimet näytetään).
Lopuksi suoritamme komennon .quit, joka sulkee SQLite-tulkin.
Tietokanta tiedostossa
Käynnistyksen yhteydessä SQLite-tulkille voi antaa parametrina tiedoston, johon tietokanta tallennetaan. Tällöin tietokannan sisältö säilyy tallessa tulkin sulkemisen jälkeen.
Seuraavassa esimerkissä tietokanta tallennetaan tiedostoon testi.db. Tämän ansiosta tietokannan sisältö on edelleen tallessa, kun tulkki käynnistetään uudestaan.
$ sqlite3 testi.db
SQLite version 3.11.0 2016-02-15 17:29:24
Enter ".help" for usage hints.
sqlite> CREATE TABLE Tuotteet (id INTEGER PRIMARY KEY, nimi TEXT, hinta INTEGER);
sqlite> .tables
Tuotteet
sqlite> .quit
$ sqlite3 testi.db
SQLite version 3.11.0 2016-02-15 17:29:24
Enter ".help" for usage hints.
sqlite> .tables
Tuotteet
sqlite> .quit
Komennot tiedostosta
Voimme myös ohjata SQLite-tulkille tiedoston, jossa olevat komennot suoritetaan peräkkäin. Tämän avulla voimme automatisoida komentojen suorittamista. Esimerkiksi voimme laatia seuraavan tiedoston komennot.sql:
CREATE TABLE Tuotteet (id INTEGER PRIMARY KEY, nimi TEXT, hinta INTEGER);
INSERT INTO Tuotteet (nimi,hinta) VALUES ('retiisi',7);
INSERT INTO Tuotteet (nimi,hinta) VALUES ('porkkana',5);
INSERT INTO Tuotteet (nimi,hinta) VALUES ('nauris',4);
INSERT INTO Tuotteet (nimi,hinta) VALUES ('lanttu',8);
INSERT INTO Tuotteet (nimi,hinta) VALUES ('selleri',4);
.mode column
.headers on
SELECT * FROM Tuotteet;
Tämän jälkeen voimme ohjata komennot tiedostosta tulkille näin:
$ sqlite3 < komennot.sql
id nimi hinta
---------- ---------- ----------
1 retiisi 7
2 porkkana 5
3 nauris 4
4 lanttu 8
5 selleri 4
3. Monen taulun kyselyt
Taulujen viittaukset
Keskeinen idea tietokannoissa on, että taulun rivi voi viitata toisen taulun riviin. Tällöin voimme muodostaa kyselyn, joka kerää tietoa useista tauluista viittausten perusteella. Käytännössä viittauksena on yleensä toisessa taulussa olevan rivin id-numero.
Esimerkki
Tarkastellaan esimerkkinä tilannetta, jossa tietokannassa on tietoa kursseista ja niiden opettajista. Oletamme, että jokaisella kurssilla on yksi opettaja ja sama opettaja voi opettaa monta kurssia.
Tallennamme tauluun Opettajat tietoa opettajista. Jokaisella opettajalla on id-numero, jolla voimme viitata siihen.
id nimi
---------- ----------
1 Kaila
2 Luukkainen
3 Kivinen
4 Laaksonen
Taulussa Kurssit on puolestaan tietoa kursseista ja jokaisen kurssin kohdalla viittaus kurssin opettajaan.
id nimi opettaja_id
---------- ---------------- -----------
1 Laskennan mallit 3
2 Ohjelmoinnin per 1
3 Ohjelmoinnin jat 1
4 Tietokantojen pe 4
5 Tietorakenteet j 3
Voimme nyt hakea kurssit opettajineen seuraavalla kyselyllä, joka hakee tietoa samaan aikaan tauluista Kurssit ja Opettajat:
SELECT
Kurssit.nimi, Opettajat.nimi
FROM
Kurssit, Opettajat
WHERE
Kurssit.opettaja_id = Opettajat.id;
Koska kyselyssä on monta taulua, ilmoitamme sarakkeiden taulut. Esimerkiksi Kurssit.nimi viittaa taulun Kurssit sarakkeeseen nimi.
Kysely antaa seuraavan tuloksen:
nimi nimi
---------------- ----------
Laskennan mallit Kivinen
Ohjelmoinnin per Kaila
Ohjelmoinnin jat Kaila
Tietokantojen pe Laaksonen
Tietorakenteet j Kivinen
Mitä tässä tapahtui?
Yllä olevassa kyselyssä uutena asiana on, että kysely koskee useaa taulua (FROM Kurssit, Opettajat), mutta mitä tämä tarkoittaa oikeastaan?
Ideana on, että kun kyselyssä on monta taulua, kyselyn tulosrivien lähtökohtana ovat kaikki tavat valita rivien yhdistelmiä tauluista. Tämän jälkeen WHERE-osan ehdoilla voi määrittää, mitkä yhdistelmät ovat kiinnostuksen kohteena.
Hyvä tapa saada ymmärrystä monen taulun kyselyn toiminnasta on tarkastella ensin kyselyä, joka hakee kaikki sarakkeet ja jossa ei ole WHERE-osaa. Yllä olevassa esimerkkitilanteessa tällainen kysely on seuraava:
SELECT
*
FROM
Kurssit, Opettajat;
Koska taulussa Kurssit on 5 riviä ja taulussa Opettajat on 4 riviä, kyselyn tulostaulussa on 5 * 4 = 20 riviä. Tulostaulu sisältää kaikki mahdolliset tavat valita ensin jokin rivi taulusta Kurssit ja sitten jokin rivi taulusta Opettajat:
id nimi opettaja_id id nimi
---------- ---------------- ----------- ---------- ----------
1 Laskennan mallit 3 1 Kaila
1 Laskennan mallit 3 2 Luukkainen
1 Laskennan mallit 3 3 Kivinen
1 Laskennan mallit 3 4 Laaksonen
2 Ohjelmoinnin per 1 1 Kaila
2 Ohjelmoinnin per 1 2 Luukkainen
2 Ohjelmoinnin per 1 3 Kivinen
2 Ohjelmoinnin per 1 4 Laaksonen
3 Ohjelmoinnin jat 1 1 Kaila
3 Ohjelmoinnin jat 1 2 Luukkainen
3 Ohjelmoinnin jat 1 3 Kivinen
3 Ohjelmoinnin jat 1 4 Laaksonen
4 Tietokantojen pe 4 1 Kaila
4 Tietokantojen pe 4 2 Luukkainen
4 Tietokantojen pe 4 3 Kivinen
4 Tietokantojen pe 4 4 Laaksonen
5 Tietorakenteet j 3 1 Kaila
5 Tietorakenteet j 3 2 Luukkainen
5 Tietorakenteet j 3 3 Kivinen
5 Tietorakenteet j 3 4 Laaksonen
Suurin osa tulosriveistä ei ole kuitenkaan kiinnostavia, koska ne eivät liity toisiinsa mitenkään. Esimerkiksi ensimmäinen tulosrivi kertoo vain, että on olemassa kurssi Laskennan mallit ja toisaalta on olemassa opettaja Kaila. Tämän vuoksi rajaamme hakua niin, että opettajan id-numeron tulee olla sama kummankin taulun riveissä:
SELECT
*
FROM
Kurssit, Opettajat
WHERE
Kurssit.opettaja_id = Opettajat.id;
Tämän seurauksena kysely alkaa antaa mielekkäitä tuloksia:
id nimi opettaja_id id nimi
---------- ---------------- ----------- ---------- ----------
1 Laskennan mallit 3 3 Kivinen
2 Ohjelmoinnin per 1 1 Kaila
3 Ohjelmoinnin jat 1 1 Kaila
4 Tietokantojen pe 4 4 Laaksonen
5 Tietorakenteet j 3 3 Kivinen
Tämän jälkeen voimme vielä parantaa kyselyä valitsemalla meitä kiinnostavat sarakkeet:
SELECT
Kurssit.nimi, Opettajat.nimi
FROM
Kurssit, Opettajat
WHERE
Kurssit.opettaja_id = Opettajat.id;
Näin päädymme samaan tulokseen kuin aiemmin:
nimi nimi
---------------- ----------
Laskennan mallit Kivinen
Ohjelmoinnin per Kaila
Ohjelmoinnin jat Kaila
Tietokantojen pe Laaksonen
Tietorakenteet j Kivinen
Lisää ehtoja kyselyssä
Monen taulun kyselyissä WHERE-osa kytkee toisiinsa meitä kiinnostavat taulujen rivit, mutta lisäksi voimme laittaa WHERE-osaan muita ehtoja samaan tapaan kuin ennenkin. Esimerkiksi voimme suorittaa seuraavan kyselyn:
SELECT
Kurssit.nimi, Opettajat.nimi
FROM
Kurssit, Opettajat
WHERE
Kurssit.opettaja_id = Opettajat.id AND Opettajat.nimi = 'Kivinen';
Näin saamme haettua kurssit, joiden opettajana on Kivinen:
nimi nimi
---------------- ----------
Laskennan mallit Kivinen
Tietorakenteet j Kivinen
Taulujen lyhyet nimet
Voimme tiivistää monen taulun kyselyä antamalla tauluille vaihtoehtoiset lyhyet nimet, joiden avulla voimme viitata niihin kyselyssä. Esimerkiksi kysely
SELECT
Kurssit.nimi, Opettajat.nimi
FROM
Kurssit, Opettajat
WHERE
Kurssit.opettaja_id = Opettajat.id;
voidaan esittää lyhemmin näin:
SELECT
K.nimi, O.nimi
FROM
Kurssit AS K, Opettajat AS O
WHERE
K.opettaja_id = O.id;
Sana AS ei ole pakollinen, eli voimme lyhentää kyselyä lisää:
SELECT
K.nimi, O.nimi
FROM
Kurssit K, Opettajat O
WHERE
K.opettaja_id = O.id;
Saman taulun toistaminen
Monen taulun kyselyssä voi esiintyä myös monta kertaa sama taulu, kunhan niille annetaan eri nimet. Esimerkiksi seuraava kysely hakee kaikki tavat valita kahden opettajan pari:
SELECT A.nimi, B.nimi FROM Opettajat A, Opettajat B;
Kyselyn tulos on seuraava:
nimi nimi
---------- ----------
Kaila Kaila
Kaila Luukkainen
Kaila Kivinen
Kaila Laaksonen
Luukkainen Kaila
Luukkainen Luukkainen
Luukkainen Kivinen
Luukkainen Laaksonen
Kivinen Kaila
Kivinen Luukkainen
Kivinen Kivinen
Kivinen Laaksonen
Laaksonen Kaila
Laaksonen Luukkainen
Laaksonen Kivinen
Laaksonen Laaksonen
Liitostaulut
Taulujen välillä esiintyy yleensä kahdenlaisia suhteita:
-
Yksi moneen -suhde: Taulun A rivi liittyy enintään yhteen taulun B riviin. Taulun B rivi voi liittyä useaan taulun A riviin.
-
Monta moneen -suhde: Taulun A rivi voi liittyä useaan taulun B riviin. Taulun B rivi voi liittyä useaan taulun A riviin.
Tapauksessa 1 voimme lisätä tauluun A sarakkeen, joka viittaa tauluun B, kuten teimme edellisen osion esimerkissä. Tapauksessa 2 tilanne on kuitenkin hankalampi, koska yksittäinen viittaus kummankaan taulun rivissä ei riittäisi. Ratkaisuna on luoda kolmas liitostaulu, joka sisältää tiedot viittauksista.
Esimerkki
Tarkastellaan esimerkkinä tilannetta, jossa verkkokaupassa on tuotteita ja asiakkaita ja jokainen asiakas on valinnut tiettyjä tuotteita ostoskoriin. Tietyn asiakkaan korissa voi olla useita tuotteita, ja toisaalta tietty tuote voi olla usean asiakkaan korissa.
Rakennamme tietokannan niin, että siinä on kolme taulua: Tuotteet, Asiakkaat ja Ostokset. Liitostaulu Ostokset ilmaisee, mitä tuotteita on kunkin asiakkaan ostoskorissa. Sen jokainen rivi esittää yhden parin muotoa “asiakkaan x korissa on tuote y”.
Oletamme, että taulujen sisällöt ovat seuraavat:
| Tuotteet | ||
|---|---|---|
| id | nimi | hinta |
| 1 | retiisi | 7 |
| 2 | porkkana | 5 |
| 3 | nauris | 4 |
| 4 | lanttu | 8 |
| 5 | selleri | 4 |
| Asiakkaat | |
|---|---|
| id | nimi |
| 1 | Uolevi |
| 2 | Maija |
| 3 | Aapeli |
| Ostokset | |
|---|---|
| asiakas_id | tuote_id |
| 1 | 2 |
| 1 | 5 |
| 2 | 1 |
| 2 | 4 |
| 2 | 5 |
Nyt voimme hakea asiakkaat ja tuotteet seuraavasti:
SELECT
A.nimi, T.nimi
FROM
Asiakkaat A, Tuotteet T, Ostokset O
WHERE
A.id = O.asiakas_id AND T.id = O.tuote_id;
Kyselyn ideana on hakea tauluista Asiakkaat ja Tuotteet taulun Ostokset rivejä vastaavat tiedot. Jotta saamme mielekkäitä tuloksia, kytkemme rivit yhteen kahden ehdon avulla. Kysely tuottaa seuraavan tulostaulun:
nimi nimi
---------- ----------
Uolevi porkkana
Uolevi selleri
Maija retiisi
Maija lanttu
Maija selleri
Miten kysely toimii?
Voimme taas tutkia kyselyn toimintaa hakemalla kaikki sarakkeet ja poistamalla ehdot:
SELECT
*
FROM
Asiakkaat A, Tuotteet T, Ostokset O;
Tämän kyselyn tulostaulussa on kaikki tavat valita jokin asiakas, tuote ja ostokset. Tulostaulussa on 5 * 3 * 5 = 75 riviä ja se alkaa näin:
id nimi id nimi hinta asiakas_id tuote_id
---------- ---------- ---------- ---------- ---------- ---------- ----------
1 Uolevi 1 retiisi 7 1 2
1 Uolevi 1 retiisi 7 1 5
1 Uolevi 1 retiisi 7 2 1
1 Uolevi 1 retiisi 7 2 4
1 Uolevi 1 retiisi 7 2 5
1 Uolevi 2 porkkana 5 1 2
1 Uolevi 2 porkkana 5 1 5
1 Uolevi 2 porkkana 5 2 1
1 Uolevi 2 porkkana 5 2 4
1 Uolevi 2 porkkana 5 2 5
1 Uolevi 3 nauris 4 1 2
1 Uolevi 3 nauris 4 1 5
1 Uolevi 3 nauris 4 2 1
1 Uolevi 3 nauris 4 2 4
1 Uolevi 3 nauris 4 2 5
...
Sitten kun lisäämme kyselyyn ehdot, saamme rajattua kiinnostavat rivit:
SELECT
*
FROM
Asiakkaat A, Tuotteet T, Ostokset O
WHERE
A.id = O.asiakas_id AND T.id = O.tuote_id;
id nimi id nimi hinta asiakas_id tuote_id
---------- ---------- ---------- ---------- ---------- ---------- ----------
1 Uolevi 2 porkkana 5 1 2
1 Uolevi 5 selleri 4 1 5
2 Maija 1 retiisi 7 2 1
2 Maija 4 lanttu 8 2 4
2 Maija 5 selleri 4 2 5
Kun vielä määritämme halutut sarakkeet, tuloksena on lopullinen kysely:
SELECT
A.nimi, T.nimi
FROM
Asiakkaat A, Tuotteet T, Ostokset O
WHERE
A.id = O.asiakas_id AND T.id = O.tuote_id;
nimi nimi
---------- ----------
Uolevi porkkana
Uolevi selleri
Maija retiisi
Maija lanttu
Maija selleri
Lisää ehtoja kyselyyn
Voimme lisätä kyselyyn lisää ehtoja, jos haluamme saada selville muuta ostoskoreista. Esimerkiksi seuraava kysely hakee Maijan korissa olevat tuotteet:
SELECT
T.nimi
FROM
Asiakkaat A, Tuotteet T, Ostokset O
WHERE
A.id = O.asiakas_id AND T.id = O.tuote_id AND A.nimi = 'Maija';
nimi
----------
retiisi
lanttu
selleri
Seuraava kysely puolestaan kertoo, keiden korissa on selleri:
SELECT
A.nimi
FROM
Asiakkaat A, Tuotteet T, Ostokset O
WHERE
A.id = O.asiakas_id AND T.id = O.tuote_id AND T.nimi = 'selleri';
nimi
----------
Uolevi
Maija
Yhteenveto tauluista
Voimme käyttää koostefunktioita ja ryhmittelyä myös usean taulun kyselyissä. Ne käsittelevät tulostaulua samalla periaatteella kuin yhden taulun kyselyissä.
Esimerkki
Tarkastellaan edelleen tietokantaa, jossa on tuotteita, asiakkaita ja ostoksia:
| Tuotteet | ||
|---|---|---|
| id | nimi | hinta |
| 1 | retiisi | 7 |
| 2 | porkkana | 5 |
| 3 | nauris | 4 |
| 4 | lanttu | 8 |
| 5 | selleri | 4 |
| Asiakkaat | |
|---|---|
| id | nimi |
| 1 | Uolevi |
| 2 | Maija |
| 3 | Aapeli |
| Ostokset | |
|---|---|
| asiakas_id | tuote_id |
| 1 | 2 |
| 1 | 5 |
| 2 | 1 |
| 2 | 4 |
| 2 | 5 |
Seuraava kysely luo yhteenvedon, joka näyttää jokaisesta asiakkaasta, montako tuotetta hänen ostoskorissaan on ja mikä on tuotteiden yhteishinta.
SELECT
A.nimi, COUNT(T.id), SUM(T.hinta)
FROM
Asiakkaat A, Tuotteet T, Ostokset O
WHERE
A.id = O.asiakas_id AND T.id = O.tuote_id
GROUP BY
A.id;
Kyselyn tulos on seuraava:
nimi COUNT(T.id) SUM(T.hinta)
---------- ----------- ------------
Uolevi 2 9
Maija 3 19
Uolevin korissa on siis 2 tavaraa, joiden yhteishinta on 9, ja Maijan korissa on 3 tavaraa, joiden yhteishinta on 19.
Miten kysely toimii?
Kyselyn perusta on tässä:
SELECT
*
FROM
Asiakkaat A, Tuotteet T, Ostokset O
WHERE
A.id = O.asiakas_id AND T.id = O.tuote_id;
id nimi id nimi hinta asiakas_id tuote_id
---------- ---------- ---------- ---------- ---------- ---------- ----------
1 Uolevi 2 porkkana 5 1 2
1 Uolevi 5 selleri 4 1 5
2 Maija 1 retiisi 7 2 1
2 Maija 4 lanttu 8 2 4
2 Maija 5 selleri 4 2 5
Kun kyselyyn lisätään ryhmittely GROUP BY A.id, rivit jakautuvat kahteen ryhmään sarakkeen A.id mukaan:
id nimi id nimi hinta asiakas_id tuote_id
---------- ---------- ---------- ---------- ---------- ---------- ----------
1 Uolevi 2 porkkana 5 1 2
1 Uolevi 5 selleri 4 1 5
id nimi id nimi hinta asiakas_id tuote_id
---------- ---------- ---------- ---------- ---------- ---------- ----------
2 Maija 1 retiisi 7 2 1
2 Maija 4 lanttu 8 2 4
2 Maija 5 selleri 4 2 5
Näille ryhmille lasketaan sitten tuotteiden määrä COUNT(T.id) sekä ostosten yhteishinta SUM(T.hinta).
Huomaa, että kyselyssä ryhmittely tapahtuu sarakkeen A.id mukaan, mutta kyselyssä haetaan sarake A.nimi. Tämä on sinänsä järkevää, koska sarake A.id määrää sarakkeen A.nimi, ja kysely toimii mainiosti SQLitessä. Muissa tietokannoissa vaatimuksena voi kuitenkin olla, että sellaisenaan haettavan sarakkeen tulee aina esiintyä myös ryhmittelyssä. Tällöin ryhmittelyn tulisi olla GROUP BY A.id, A.nimi.
Puuttuvan rivin ongelma
Kysely toimii sinänsä hyvin, mutta jotain puuttuu:
nimi COUNT(T.id) SUM(T.hinta)
---------- ----------- ------------
Uolevi 2 9
Maija 3 19
Kyselyn puutteena on vielä, että tuloksissa ei ole lainkaan kolmatta tietokannassa olevaa asiakasta eli Aapelia. Koska Aapelin korissa ei ole mitään, Aapelin rivi ei yhdisty minkään muun rivin kanssa eikä pääse osaksi tulostaulua.
Olemme törmänneet ongelmaan, mutta onneksi löydämme siihen ratkaisun pian.
JOIN-syntaksi
Tähän mennessä olemme hakeneet tietoa tauluista listaamalla taulut kyselyn FROM-osassa, mikä toimii yleensä hyvin. Kuitenkin joskus on tarpeen vaihtoehtoinen JOIN-syntaksi. Siitä on hyötyä silloin, kun kyselyn tuloksesta näyttää “puuttuvan” tietoa.
Kyselytavat
Seuraavassa on kaksi tapaa toteuttaa sama kysely, ensin käyttäen ennestään tuttua tapaa ja sitten käyttäen JOIN-syntaksia.
SELECT
Kurssit.nimi, Opettajat.nimi
FROM
Kurssit, Opettajat
WHERE
Kurssit.opettaja_id = Opettajat.id;
SELECT
Kurssit.nimi, Opettajat.nimi
FROM
Kurssit JOIN Opettajat ON Kurssit.opettaja_id = Opettajat.id;
JOIN-syntaksissa taulujen nimien välissä esiintyy sana JOIN ja lisäksi taulujen rivit toisiinsa kytkevä ehto annetaan erillisessä ON-osassa.
Tässä tapauksessa JOIN-syntaksi on vain vaihtoehtoinen tapa toteuttaa kysely eikä se tuo mitään uutta. Kuitenkin näemme seuraavaksi, miten voimme laajentaa syntaksia niin, että se antaa meille uusia mahdollisuuksia kyselyissä.
Esimerkki
Tarkastellaan esimerkkinä tilannetta, jossa tietokannassa on tutut taulut Kurssit ja Opettajat, mutta taulussa Kurssit yhdeltä kurssilta puuttuu opettaja:
id nimi opettaja_id
---------- ---------------- -----------
1 Laskennan mallit 3
2 Ohjelmoinnin per 1
3 Ohjelmoinnin jat 1
4 Tietokantojen pe
5 Tietorakenteet j 3
Rivin 4 sarakkeessa opettaja_id on arvo NULL, joten jos suoritamme jommankumman äskeisen kyselyn, ongelmaksi tulee, että rivi 4 ei täsmää mihinkään taulun Opettajat riviin. Tämän seurauksena tulostauluun ei tule riviä kurssista Tietokantojen perusteet:
nimi nimi
---------------- ----------
Laskennan mallit Kivinen
Ohjelmoinnin per Kaila
Ohjelmoinnin jat Kaila
Tietorakenteet j Kivinen
Ratkaisu ongelmaan on käyttää LEFT JOIN -syntaksia, joka tarkoittaa, että mikäli jokin vasemman taulun rivi ei yhdisty mihinkään oikean taulun riviin, kyseinen vasemman taulun rivi pääsee silti mukaan yhdeksi riviksi tulostauluun. Kyseisellä rivillä jokaisen oikeaan tauluun perustuvan sarakkeen arvona on NULL.
Tässä tapauksessa voimme toteuttaa kyselyn näin:
SELECT
Kurssit.nimi, Opettajat.nimi
FROM
Kurssit LEFT JOIN Opettajat ON Kurssit.opettaja_id = Opettajat.id;
Nyt tulostauluun ilmestyy myös kurssi Tietokantojen perusteet ilman opettajaa:
nimi nimi
---------------- ----------
Laskennan mallit Kivinen
Ohjelmoinnin per Kaila
Ohjelmoinnin jat Kaila
Tietokantojen pe
Tietorakenteet j Kivinen
Miten kysely toimii?
Jälleen hyvä tapa saada selkoa kyselystä on yksinkertaistaa sitä:
SELECT
*
FROM
Kurssit LEFT JOIN Opettajat ON Kurssit.opettaja_id = Opettajat.id;
id nimi opettaja_id id nimi
---------- ---------------- ----------- ---------- ----------
1 Laskennan mallit 3 3 Kivinen
2 Ohjelmoinnin per 1 1 Kaila
3 Ohjelmoinnin jat 1 1 Kaila
4 Tietokantojen pe
5 Tietorakenteet j 3 3 Kivinen
Tästä näkee, että koska vasemman taulun rivi 4 ei täsmää mihinkään oikean taulun riviin, niin kyseisestä rivistä tulee tulostauluun yksi rivi, jossa jokainen sarake oikean taulun osuudessa on NULL.
JOIN-kyselyperhe
Itse asiassa JOIN-kyselystä on olemassa peräti neljä eri muunnelmaa:
JOIN: toimii kuten tavallinen kahden taulun kyselyLEFT JOIN: jos vasemman taulun rivi ei yhdisty mihinkään oikean taulun riviin, se valitaan kuitenkin mukaan erikseenRIGHT JOIN: jos oikean taulun rivi ei yhdisty mihinkään vasemman taulun riviin, se valitaan kuitenkin mukaan erikseenFULL JOIN: sekä vasemmasta että oikeasta taulusta valitaan erikseen mukaan rivit, jotka eivät yhdisty toisen taulun riviin
SQLiten rajoituksena on kuitenkin, että vain kaksi ensimmäistä kyselytapaa ovat mahdollisia. Onneksi LEFT JOIN on yleensä se, mitä haluamme.
ON vs. WHERE
Sana ON on oleellinen LEFT JOIN -kyselyssä, koska se asettaa ehdon niin, että mukaan otetaan myös vasemman taulun ylimääräiset rivit:
SELECT
Kurssit.nimi, Opettajat.nimi
FROM
Kurssit LEFT JOIN Opettajat ON Kurssit.opettaja_id = Opettajat.id;
nimi nimi
---------------- ----------
Laskennan mallit Kivinen
Ohjelmoinnin per Kaila
Ohjelmoinnin jat Kaila
Tietokantojen pe
Tietorakenteet j Kivinen
Jos käytämme sen sijasta sanaa WHERE, ylimääräiset rivit jäävät pois:
SELECT
Kurssit.nimi, Opettajat.nimi
FROM
Kurssit LEFT JOIN Opettajat
WHERE
Kurssit.opettaja_id = Opettajat.id;
nimi nimi
---------------- ----------
Laskennan mallit Kivinen
Ohjelmoinnin per Kaila
Ohjelmoinnin jat Kaila
Tietorakenteet j Kivinen
Sinänsä kyselyssä voi esiintyä sekä ON että WHERE:
SELECT
Kurssit.nimi, Opettajat.nimi
FROM
Kurssit LEFT JOIN Opettajat ON Kurssit.opettaja_id = Opettajat.id
WHERE
Kurssit.nimi <> 'Ohjelmoinnin perusteet';
Tällöin ON-osa hoitaa taulujen yhdistämisen ja WHERE-osa rajaa tuloksia lisää:
nimi nimi
---------------- ----------
Laskennan mallit Kivinen
Ohjelmoinnin jat Kaila
Tietokantojen pe
Tietorakenteet j Kivinen
Jos molemmat ehdot ovatkin ON-osassa, kyselyn tulos muuttuu taas:
SELECT
Kurssit.nimi, Opettajat.nimi
FROM
Kurssit LEFT JOIN Opettajat ON Kurssit.opettaja_id = Opettajat.id AND
Kurssit.nimi <> 'Ohjelmoinnin perusteet';
nimi nimi
---------------- ----------
Laskennan mallit Kivinen
Ohjelmoinnin per
Ohjelmoinnin jat Kaila
Tietokantojen pe
Tietorakenteet j Kivinen
Yhteenveto toimivaksi
Nyt voimme pureutua aiempaan ongelmaan, jossa yhteenvetokyselystä puuttui tietoa. Tietokannassamme on edelleen seuraavat taulut:
| Tuotteet | ||
|---|---|---|
| id | nimi | hinta |
| 1 | retiisi | 7 |
| 2 | porkkana | 5 |
| 3 | nauris | 4 |
| 4 | lanttu | 8 |
| 5 | selleri | 4 |
| Asiakkaat | |
|---|---|
| id | nimi |
| 1 | Uolevi |
| 2 | Maija |
| 3 | Aapeli |
| Ostokset | |
|---|---|
| asiakas_id | tuote_id |
| 1 | 2 |
| 1 | 5 |
| 2 | 1 |
| 2 | 4 |
| 2 | 5 |
Muodostimme yhteenvedon ostoskoreista seuraavalla kyselyllä:
SELECT
A.nimi, COUNT(T.id), SUM(T.hinta)
FROM
Asiakkaat A, Tuotteet T, Ostokset O
WHERE
A.id = O.asiakas_id AND T.id = O.tuote_id
GROUP BY
A.id;
Kuitenkin ongelmaksi tuli, että Aapeli puuttuu yhteenvedosta:
nimi COUNT(T.id) SUM(T.hinta)
---------- ----------- ------------
Uolevi 2 9
Maija 3 19
Ratkaisu
Ongelman syynä on, että Aapelin ostoskori on tyhjä eli kun kysely valitsee yhdistelmiä taulujen riveistä, ei ole mitään sellaista riviä, jolla esiintyisi Aapeli. Ratkaisu ongelmaan on käyttää LEFT JOIN -syntaksia näin:
SELECT
A.nimi, COUNT(T.id), SUM(T.hinta)
FROM
Asiakkaat A LEFT JOIN Ostokset O ON A.id = O.asiakas_id
LEFT JOIN Tuotteet T ON T.id = O.tuote_id
GROUP BY
A.id;
Nyt myös Aapeli ilmestyy mukaan yhteenvetoon:
nimi COUNT(T.id) SUM(T.hinta)
---------- ----------- ------------
Uolevi 2 9
Maija 3 19
Aapeli 0
Koska Aapelin ostoskorissa ei ole tuotteita, hintojen summaksi tulee NULL. Voimme vielä parantaa kyselyä IFNULL-funktion avulla:
SELECT
A.nimi, COUNT(T.id), IFNULL(SUM(T.hinta),0)
FROM
Asiakkaat A LEFT JOIN Ostokset O ON A.id = O.asiakas_id
LEFT JOIN Tuotteet T ON T.id = O.tuote_id
GROUP BY
A.id;
Tämän seurauksena mahdollinen NULL muuttuu arvoksi 0:
nimi COUNT(T.id) IFNULL(SUM(T.hinta),0)
---------- ----------- ----------------------
Uolevi 2 9
Maija 3 19
Aapeli 0 0
Palaamme NULL-arvojen käsittelyyn tarkemmin myöhemmin.
Miten kysely toimii?
Kun kyselyssä on useita LEFT JOIN -osia, tulkintana on, että ne yhdistävät tauluja vasemmalta oikealle. Yllä olevassa kyselyssä voimme ajatella, että ensimmäinen vaihe yhdistää taulut Asiakkaat ja Ostokset:
SELECT
*
FROM
Asiakkaat A LEFT JOIN Ostokset O ON A.id = O.asiakas_id;
id nimi asiakas_id tuote_id
---------- ---------- ---------- ----------
1 Uolevi 1 2
1 Uolevi 1 5
2 Maija 2 1
2 Maija 2 4
2 Maija 2 5
3 Aapeli
Toinen vaihe puolestaan yhdistää yllä olevan tulostaulun ja taulun Tuotteet:
SELECT
*
FROM
Asiakkaat A LEFT JOIN Ostokset O ON A.id = O.asiakas_id
LEFT JOIN Tuotteet T ON T.id = O.tuote_id;
id nimi asiakas_id tuote_id id nimi hinta
---------- ---------- ---------- ---------- ---------- ---------- ----------
1 Uolevi 1 2 2 porkkana 5
1 Uolevi 1 5 5 selleri 4
2 Maija 2 1 1 retiisi 7
2 Maija 2 4 4 lanttu 8
2 Maija 2 5 5 selleri 4
3 Aapeli
Molemmissa vaiheissa Aapeli pääsee osaksi tulostaulua, koska kyseinen rivi ei täsmää minkään oikean taulun rivin kanssa.
4. Lisää SQL-kielestä
Tyypit ja lausekkeet
SQL-kielessä esiintyy tyyppejä ja lausekkeita samaan tapaan kuin ohjelmoinnissa. Olemme jo nähneet monia esimerkkejä SQL-komennoista, mutta nyt on hyvä hetki tutustua syvällisemmin kielen rakenteeseen.
Jokainen tietokantajärjestelmä toteuttaa tyypit ja lausekkeet vähän omalla tavallaan ja tietokantojen toiminnassa on paljon pieniä eroja. Niinpä aiheeseen liittyvät yksityiskohdat kannattaa tarkastaa käytetyn tietokannan dokumentaatiosta.
Tyypit
Taulun määrittelyssä jokaiselle sarakkeelle annetaan tyyppi:
CREATE TABLE Elokuvat(id INTEGER PRIMARY KEY, nimi TEXT, vuosi INTEGER);
Tässä sarakkeen nimi tyyppi on TEXT (merkkijono) ja sarakkeen vuosi tyyppi on INTEGER (kokonaisluku). Nämä ovat yleisimmät tyypit, jotka ovat saatavilla näillä nimillä monissa tietokannoissa. Esimerkkejä muista yleisistä tyypeistä ovat TIMESTAMP (ajanhetki), REAL (liukuluku) ja BLOB (raakadata).
TEXT vs. VARCHAR
Perinteikäs tapa tallentaa merkkijono SQL:ssä on käyttää tyyppiä VARCHAR, jossa annetaan suluissa merkkijonon maksimipituus. Esimerkiksi tyyppi VARCHAR(10) tarkoittaa, että merkkijonossa voi olla enintään 10 merkkiä.
Tämä on muistuma vanhan ajan ohjelmoinnista, jossa merkkijono saatettiin esittää kiinteän pituisena merkkitaulukkona. Tyyppi TEXT on kuitenkin mukavampi, koska siinä ei tarvitse keksiä maksimipituutta.
SQLiten tyypit
Erikoinen piirre SQLiten toteutuksessa on, että taulun määrittelyssä esiintyvä tyyppi on vain ohje, mitä tyyppiä sarakkeessa tulisi olla. Voimme kuitenkin olla välittämättä ohjeesta ja vaikkapa tallentaa kokonaisluvun kohdalle merkkijonon:
INSERT INTO Elokuvat (nimi,vuosi) VALUES ('Lumikki','abc');
Lisäksi tyypin nimenä voi olla mikä tahansa merkkijono, vaikka SQLitessä ei olisi sellaista tyyppiä. Tämän avulla voimme esimerkiksi määritellä sarakkeen, johon on tarkoitus tallentaa ajanhetki:
CREATE TABLE Tapahtumat(id INTEGER PRIMARY KEY, paiva TIMESTAMP, viesti TEXT);
SQLitessä ei ole tyyppiä TIMESTAMP, vaan ajanhetkiä käsitellään merkkijonoina, mutta tässä kuitenkin sarakkeen tyyppi ilmaisee, mitä siihen on tarkoitus tallentaa.
Lausekkeet
Lauseke on SQL-komennon osa, jolla on tietty arvo. Esimerkiksi kyselyssä
SELECT hinta FROM Tuotteet WHERE nimi='retiisi';
on neljä lauseketta: hinta, nimi, 'retiisi' ja nimi='retiisi'. Lausekkeet hinta ja nimi saavat arvonsa rivin sarakkeesta, lauseke 'retiisi' on merkkijonovakio ja lauseke nimi='retiisi' on totuusarvoinen.
Voimme rakentaa monimutkaisempia lausekkeita samaan tapaan kuin ohjelmoinnissa. Esimerkiksi kysely
SELECT hinta*5 FROM Tuotteet;
antaa jokaisen tuotteen hinnan viisinkertaisena ja kysely
SELECT nimi FROM Tuotteet WHERE hinta%2 = 0;
hakee tuotteet, joiden hinta on parillinen.
Hyvä tapa testata SQL:n lausekkeiden toimintaa on keskustella tietokannan kanssa tekemällä kyselyitä, jotka eivät hae tietoa mistään taulusta vaan laskevat vain tietyn lausekkeen arvon. Keskustelu voi näyttää vaikkapa seuraavalta:
sqlite> SELECT 2*(1+3);
8
sqlite> SELECT 'tes' || 'ti';
testi
sqlite> SELECT 3 < 5;
1
Ensimmäinen kysely laskee lausekkeen 2*(1+3) arvon. Toinen kysely yhdistää ||-operaattorilla
merkkijonot 'tes' ja 'ti' merkkijonoksi 'testi'. Kolmas kysely puolestaan määrittää ehtolausekkeen 3 < 5 arvon. Tästä näkee, että SQLitessä kokonaisluku ilmaisee totuusarvon: 1 on tosi ja 0 on epätosi.
Monet SQL:n lausekkeisiin liittyvät asiat ovat tuttuja ohjelmoinnista:
- laskutoimitukset:
+,-,*,/,% - vertaileminen:
=,<>,<,<=,>,>= - ehtojen yhdistys:
AND,OR,NOT
Näiden lisäksi SQL:ssä on kuitenkin myös erikoisempia ominaisuuksia, joiden tuntemisesta on välillä hyötyä. Seuraavassa on joitakin niistä:
BETWEEN
Lauseke x BETWEEN a AND b on tosi, jos x on vähintään a ja enintään b. Esimerkiksi kysely
SELECT * FROM Tuotteet WHERE hinta BETWEEN 4 AND 6;
hakee tuotteet, joiden hinta on vähintään 4 ja korkeintaan 6. Voimme toki kirjoittaa samalla tavalla toimivan kyselyn myös näin:
SELECT * FROM Tuotteet WHERE hinta >= 4 AND hinta <= 6;
CASE
Rakenne CASE mahdollistaa ehtolausekkeen tekemisen. Siinä voi olla yksi tai useampi WHEN-osa sekä mahdollinen ELSE-osa. Esimerkiksi kysely
SELECT nimi, CASE WHEN hinta>5 THEN 'kallis' ELSE 'halpa' END FROM Tuotteet;
hakee kunkin tuotteen nimen sekä tiedon siitä, onko tuote kallis vai halpa. Tässä tuote on kallis, jos sen hinta on yli 5, ja muuten halpa.
IN
Lauseke x IN (...) on tosi, jos x on jokin annetuista arvoista. Esimerkiksi kysely
SELECT * FROM Tuotteet WHERE nimi IN ('lanttu','nauris','selleri');
hakee tuotteet, joiden nimi on lanttu, nauris tai selleri.
LIKE
Lauseke s LIKE p on tosi, jos merkkijono s vastaa kuvausta p. Kuvauksessa voi käyttää erikoismerkkejä _ (mikä tahansa yksittäinen merkki) sekä % (mikä tahansa määrä mitä tahansa merkkejä). Esimerkiksi kysely
SELECT * FROM Tuotteet WHERE nimi LIKE '%ri%';
hakee tuotteet, joiden nimen osana esiintyy merkkijono “ri” (kuten nauris ja selleri).
Funktiot
Lausekkeiden osana voi esiintyä myös funktioita samaan tapaan kuin ohjelmoinnissa. Tässä on esimerkkinä joitakin SQLiten funktioita:
ABS(x)antaa luvunxitseisarvonLENGTH(s)antaa merkkijononspituudenLOWER(s)muuttaa merkkijononskirjaimet pieniksiMAX(x,y)antaa suuremman luvuistaxjayMIN(x,y)antaa pienemmän luvuistaxjayRANDOM()antaa satunnaisen luvunROUND(x,d)antaa luvunxpyöristettynäddesimaalin tarkkuudelleSUBSTR(s,a,b)antaa merkkijononskohdastaaalkaenbmerkkiäUPPER(s)muuttaa merkkijononskirjaimet suuriksi
Esimerkiksi kysely
SELECT * FROM Tuotteet WHERE LENGTH(nimi)=6;
hakee tuotteet, joiden nimessä on kuusi kirjainta (kuten lanttu ja nauris). Kysely
SELECT SUBSTR(nimi,1,1), COUNT(*) FROM Tuotteet GROUP BY SUBSTR(nimi,1,1);
ryhmittelee tuotteet ensimmäisen kirjaimen mukaan ja ilmoittaa kullakin kirjaimella alkavien tuotteiden määrät. Kysely
SELECT * FROM Tuotteet ORDER BY RANDOM();
puolestaan antaa rivit satunnaisessa järjestyksessä, koska järjestys ei perustu minkään sarakkeen sisältöön vaan satunnaiseen arvoon.
ORDER BY ja lausekkeet
Voisi kuvitella, että kyselyssä
SELECT * FROM Tuotteet ORDER BY 1;
rivit järjestetään lausekkeen 1 mukaan. Koska lausekkeen arvo on joka rivillä 1, tämä ei tuottaisi mitään erityistä järjestystä. Näin ei kuitenkaan ole, vaan 1 järjestää rivit ensimmäisen sarakkeen mukaan, 2 toisen sarakkeen mukaan, jne. Tämä on siis vaihtoehtoinen tapa ilmaista sarake, johon järjestys perustuu.
Kuitenkin jos ORDER BY -osassa oleva lauseke on jotain muuta kuin yksittäinen luku (kuten RANDOM()), rivit järjestetään kyseisen lausekkeen mukaisesti.
NULL-arvot
NULL on erityinen arvo, joka ilmaisee, että taulun sarakkeessa ei ole tietoa tai jokin kyselyn osa ei tuottanut tietoa. NULL on tietyissä tilanteissa kätevä, mutta voi aiheuttaa myös yllätyksiä.
NULL on selkeästi eri asia kuin luku 0. Jos NULL esiintyy laskun osana, niin koko laskun tulokseksi tulee NULL. SQLite-tulkki näyttää tällöin vain tyhjän rivin:
sqlite> SELECT NULL;
sqlite> SELECT 5+NULL;
sqlite> SELECT 2*NULL+1;
Myöskään tavallinen vertailu ei tuota tulosta, jos verrattavana on NULL:
sqlite> SELECT 5 = NULL;
sqlite> SELECT 5 <> NULL;
Tämä on yllättävää, koska yleensä lausekkeille a ja b pätee joko a = b tai a <> b. Voimme kuitenkin tutkia erityisen syntaksin IS NULL avulla, onko lausekkeen arvo NULL:
sqlite> SELECT 5 IS NULL;
0
sqlite> SELECT NULL IS NULL;
1
Sarakkeen puuttuva tieto
NULL-arvon yksi käyttötarkoitus on ilmaista, että jossain sarakkeessa ei ole tietoa. Esimerkiksi seuraavassa taulussa Elokuvat Dumbon vuosi puuttuu, joten sen kohdalla on NULL:
id nimi vuosi
---------- ---------- ----------
1 Lumikki 1937
2 Fantasia 1940
3 Pinocchio 1940
4 Dumbo
5 Bambi 1942
Kun haemme ensin vuoden 1940 elokuvat ja sitten kaikki elokuvat muilta vuosilta, saamme seuraavat tulokset:
SELECT * FROM Elokuvat WHERE vuosi=1940;
id nimi vuosi
---------- ---------- ----------
2 Fantasia 1940
3 Pinocchio 1940
SELECT * FROM Elokuvat WHERE vuosi<>1940;
id nimi vuosi
---------- ---------- ----------
1 Lumikki 1937
5 Bambi 1942
Koska Dumbolla ei ole vuotta, emme saa sitä kummassakaan kyselyssä, mikä on yllättävä ilmiö. Voimme kuitenkin hakea näin elokuvat, joilla ei ole vuotta:
SELECT * FROM Elokuvat WHERE vuosi IS NULL;
id nimi vuosi
---------- ---------- ----------
4 Dumbo
NULL-arvo koostefunktiossa
Kun koostefunktion sisällä on lauseke (kuten sarake), riviä ei lasketa mukaan, jos lausekkeen arvo on NULL. Tarkastellaan esimerkkinä seuraavaa taulua Tyontekijat:
id nimi yritys palkka
---------- ---------- ---------- ----------
1 Anna Google 8000
2 Liisa Google 7500
3 Kaaleppi Amazon
4 Uolevi Amazon
5 Maija Google 9500
Taulussa Googlen työntekijöillä on ilmoitettu palkka, mutta Amazonin työntekijöillä ei. Koostefunktio COUNT(palkka) laskee mukaan vain rivit, joissa palkka on ilmoitettu:
SELECT COUNT(palkka) FROM Tyontekijat WHERE yritys='Google';
COUNT(palkka)
-------------
3
SELECT COUNT(palkka) FROM Tyontekijat WHERE yritys='Amazon';
COUNT(palkka)
-------------
0
Kun sitten laskemme palkkojen summia koostefunktiolla SUM(palkka), saamme seuraavat tulokset:
SELECT SUM(palkka) FROM Tyontekijat WHERE yritys='Google';
SUM(palkka)
-----------
25000
SELECT SUM(palkka) FROM Tyontekijat WHERE yritys='Amazon';
SUM(palkka)
-----------
Tämä on vähän yllättävää, koska voisi myös odottaa tyhjän summan olevan 0 eikä NULL.
NULL-arvon muuttaminen
Funktio IFNULL(a,b) palauttaa arvon a, jos a ei ole NULL, ja muuten arvon b:
sqlite> SELECT IFNULL(5,0);
IFNULL(5,0)
-----------
5
sqlite> SELECT IFNULL(NULL,0);
IFNULL(NULL,0)
--------------
0
Yllä oleva tapa on tyypillinen tapa käyttää funktiota: kun toinen parametri on 0, niin funktio muuttaa mahdollisen NULL-arvon nollaksi. Tästä on hyötyä esimerkiksi LEFT JOIN -kyselyissä
SUM-funktion kanssa.
Yleisempi funktio on COALESCE(...), jolle annetaan lista arvoista. Funktio palauttaa listan ensimmäisen arvon, joka ei ole NULL, tai arvon NULL, jos jokainen arvo on NULL. Jos funktiolla on kaksi parametria, se toimii samoin kuin IFNULL.
sqlite> SELECT COALESCE(1,2,3);
COALESCE(1,2,3)
---------------
1
sqlite> SELECT COALESCE(NULL,2,3);
COALESCE(NULL,2,3)
------------------
2
sqlite> SELECT COALESCE(NULL,NULL,3);
COALESCE(NULL,NULL,3)
---------------------
3
sqlite> SELECT COALESCE(NULL,NULL,NULL);
COALESCE(NULL,NULL,NULL)
------------------------
Tulosrivien rajaus
Kun lisäämme kyselyn loppuun LIMIT x, kysely antaa vain x ensimmäistä tulosriviä. Esimerkiksi LIMIT 3 tarkoittaa, että kysely antaa kolme ensimmäistä tulosriviä.
Yleisempi muoto on LIMIT x OFFSET y, mikä tarkoittaa, että haluamme x riviä kohdasta y alkaen (0-indeksoituna). Esimerkiksi LIMIT 3 OFFSET 1 tarkoittaa, että kysely antaa toisen, kolmannen ja neljännen tulosrivin.
Tarkastellaan esimerkkinä kyselyä, joka hakee tuotteita halvimmasta kalleimpaan:
SELECT * FROM Tuotteet ORDER BY hinta;
Kyselyn tuloksena on seuraava tulostaulu:
id nimi hinta
---------- ---------- ----------
3 nauris 2
5 selleri 4
2 porkkana 5
1 retiisi 7
4 lanttu 8
Saamme haettua kolme halvinta tuotetta seuraavasti:
SELECT * FROM Tuotteet ORDER BY hinta LIMIT 3;
Kyselyn tulos on seuraava:
id nimi hinta
---------- ---------- ----------
3 nauris 2
5 selleri 4
2 porkkana 5
Seuraava kysely puolestaan hakee kolme halvinta tuotetta toiseksi halvimmasta tuotteesta alkaen:
SELECT * FROM Tuotteet ORDER BY hinta LIMIT 3 OFFSET 1;
Tämän kyselyn tulos on seuraava:
id nimi hinta
---------- ---------- ----------
5 selleri 4
2 porkkana 5
1 retiisi 7
Alikyselyt
Alikysely on SQL-komennon osana oleva lauseke, jonka arvo syntyy jonkin kyselyn perusteella. Voimme rakentaa alikyselyjä samaan tapaan kuin varsinaisia kyselyjä ja toteuttaa niiden avulla hakuja, joita olisi vaikea saada aikaan muuten.
Esimerkki
Tarkastellaan esimerkkinä tilannetta, jossa tietokannassa on pelaajien tuloksia taulussa Tulokset. Oletamme, että taulun sisältö on seuraava:
id nimi tulos
---------- ---------- ----------
1 Uolevi 120
2 Maija 80
3 Liisa 120
4 Aapeli 45
5 Kaaleppi 115
Haluamme nyt selvittää ne pelaajat, jotka ovat saavuttaneet korkeimman tuloksen, eli kyselyn tulisi palauttaa Uolevi ja Liisa. Saamme tämän aikaan alikyselyllä seuraavasti:
SELECT
nimi, tulos
FROM
Tulokset
WHERE
tulos = (SELECT MAX(tulos) FROM Tulokset);
Kyselyn tuloksena on:
nimi tulos
---------- ----------
Uolevi 120
Liisa 120
Tässä kyselyssä alikysely on SELECT MAX(tulos) FROM Tulokset, joka antaa suurimman taulussa olevan tuloksen eli tässä tapauksessa arvon 120. Huomaa, että alikysely tulee kirjoittaa sulkujen sisään, jotta se ei sekoitu pääkyselyyn.
Alikyselyn laatiminen
Alikysely voi esiintyä melkein missä tahansa kohtaa kyselyssä, ja se voi tilanteesta riippuen palauttaa yksittäisen arvon, listan arvoista tai kokonaisen taulun.
Alikysely sarakkeessa
Seuraavassa kyselyssä alikyselyn avulla luodaan kolmas sarake, joka näyttää pelaajan tuloksen eron ennätystulokseen:
SELECT
nimi, tulos, (SELECT MAX(tulos) FROM Tulokset)-tulos
FROM
Tulokset;
nimi tulos (SELECT MAX(tulos) FROM Tulokset)-tulos
---------- ---------- ---------------------------------------
Uolevi 120 0
Maija 80 40
Liisa 120 0
Aapeli 45 75
Kaaleppi 115 5
Alikysely tauluna
Seuraavassa kyselyssä alikysely luo taulun, jossa on kolme parasta tulosta. Näiden tulosten summa (120+120+115) lasketaan pääkyselyssä.
SELECT
SUM(tulos)
FROM
(SELECT * FROM Tulokset ORDER BY tulos DESC LIMIT 3);
SUM(tulos)
----------
355
Tässä avainsana LIMIT rajaa tulostaulua niin, että siinä on vain kolme ensimmäistä riviä.
Huomaa, että yhtä kyselyä käyttämällä saisimme väärän tuloksen:
SELECT SUM(tulos) FROM Tulokset ORDER BY tulos DESC LIMIT 3;
SUM(tulos)
----------
480
Tässä tulostaulussa on vain yksi rivi, jossa on kaikkien tulosten summa (480). Niinpä kyselyn lopussa oleva LIMIT 3 ei vaikuta mitenkään tulokseen.
Alikysely listana
Seuraava kysely hakee pelaajat, joiden tulos kuuluu kolmen parhaimman joukkoon. Alikysely palauttaa listan tuloksista IN-lauseketta varten.
SELECT
nimi
FROM
Tulokset
WHERE
tulos IN (SELECT tulos FROM Tulokset ORDER BY tulos DESC LIMIT 3);
nimi
----------
Uolevi
Liisa
Kaaleppi
Riippuva alikysely
Alikysely on mahdollista toteuttaa myös niin, että sen toiminta riippuu pääkyselyssä käsiteltävästä rivistä. Näin on seuraavassa kyselyssä:
SELECT
nimi, tulos, (SELECT COUNT(*) FROM Tulokset WHERE tulos > T.tulos)
FROM
Tulokset T;
Tämän kysely laskee jokaiselle pelaajalle, monenko pelaajan tulos on parempi kuin pelaajan oma tulos. Esimerkiksi Maijalle vastaus on 3, koska Uolevin, Liisan ja Kaalepin tulos on parempi. Kysely antaa seuraavan tuloksen:
nimi tulos (SELECT COUNT(*) FROM Tulokset WHERE tulos > T.tulos)
---------- ---------- -----------------------------------------------------
Uolevi 120 0
Maija 80 3
Liisa 120 0
Aapeli 45 4
Kaaleppi 115 2
Koska taulu Tulokset esiintyy kahdessa roolissa alikyselyssä, pääkyselyn taululle on annettu nimi T. Tämän ansiosta alikyselyssä on selvää, että halutaan laskea rivejä, joiden tulos on parempi kuin pääkyselyssä käsiteltävän rivin tulos.
Milloin käyttää alikyselyä?
Melko usein alikysely on vaihtoehtoinen tapa toteuttaa kysely, jonka voisi tehdä jotenkin muutenkin. Esimerkiksi molemmat seuraavat kyselyt hakevat tuotteiden nimet asiakkaan 1 ostoskorissa:
SELECT
T.nimi
FROM
Tuotteet T, Ostokset O
WHERE
T.id = O.tuote_id AND O.asiakas_id = 1;
SELECT
nimi
FROM
Tuotteet
WHERE
id IN (SELECT tuote_id FROM Ostokset WHERE asiakas_id = 1);
Ensimmäinen kysely on tyypillinen kahden taulun kysely, kun taas toinen kysely valikoi tuotteet alikyselyn avulla. Kumpi kysely on parempi?
Ensimmäinen kysely on parempi, koska tämä on tarkoitettu tapa hakea SQL:ssä tietoa tauluista viittausten avulla. Toinen kysely toimii sinänsä, mutta se poikkeaa totutusta eikä tietokantajärjestelmä myöskään pysty ehkä suorittamaan sitä yhtä tehokkaasti.
Alikyselyä kannattaa käyttää vain silloin, kun siihen on todellinen syy. Jos kyselyn voi tehdä helposti usean taulun kyselyllä, tämä on yleensä parempi ratkaisu.
Lisää tekniikoita
Tässä osiossa on lisää näytteitä SQL:n mahdollisuuksista. Näistä tekniikoista on hyötyä joidenkin SQL Trainerin vaikeiden tehtävien ratkaisemisessa.
Kumulatiivinen summa
Hyödyllinen taito SQL:ssä on osata laskea kumulatiivinen summa eli jokaiselle riville summa sarakkeen luvuista kyseiselle riville asti. Tarkastellaan esimerkiksi seuraavaa taulua:
id tulos
---------- ----------
1 200
2 100
3 400
4 100
Voimme laskea kumulatiivisen summan kahden taulun kyselyllä näin:
SELECT
A.id, SUM(B.tulos)
FROM
Tulokset A, Tulokset B
WHERE
B.id <= A.id
GROUP BY
A.id;
id SUM(B.tulos)
---------- ------------
1 200
2 300
3 700
4 800
Tässä on ideana, että summa lasketaan taulun A riville ja taulusta B haetaan kaikki rivit, joiden id on pienempi tai sama kuin taulun A rivillä. Halutut summat saadaan laskettua SUM-funktiolla ryhmittelyn jälkeen.
Vastaavaa tekniikkaa voi käyttää muissakin tilanteissa, jos haluamme laskea tuloksen, joka riippuu jotenkin kaikista “pienemmistä” riveistä taulussa.
Sisäkkäiset koosteet
Tarkastellaan tilannetta, jossa haluamme selvittää, mikä on suurin määrä elokuvia, jotka ovat ilmestyneet samana vuonna. Esimerkiksi seuraavassa taulussa haluttu tulos on 2, koska vuonna 1940 ilmestyi kaksi elokuvaa.
id nimi vuosi
---------- ---------- ----------
1 Lumikki 1937
2 Fantasia 1940
3 Pinocchio 1940
4 Dumbo 1941
5 Bambi 1942
Tämä on vähän hankalalta vaikuttava tilanne, koska meidän tulisi tehdä sisäkkäin kyselyt COUNT, joka laskee ilmestymismääriä, ja sitten MAX, joka hakee suurimman arvon. SQL ei salli kuitenkaan kyselyä SELECT MAX(COUNT(vuosi)) tai vastaavaa.
Voimme ottaa kuitenkin lähtökohdaksi kyselyn, joka ryhmittelee elokuvat vuoden mukaan ja hakee jokaisesta ryhmästä elokuvien määrän:
SELECT COUNT(*) FROM Elokuvat GROUP BY vuosi;
COUNT(*)
----------
1
2
1
1
Näistä luvuista pitää vielä saada haettua suurin, mikä onnistuu alikyselyn avulla. Tässä tapauksessa kätevä tapa on käyttää alikyselyä niin, että sen tulos on pääkyselyn FROM-osassa, jolloin alikysely luo taulun, josta pääkysely hakee tietoa:
SELECT MAX(c) FROM (SELECT COUNT(*) c FROM Elokuvat GROUP BY vuosi);
MAX(c)
----------
2
Entä voisiko tehtävän ratkaista ilman alikyselyä? Kyllä, koska voimme järjestää tulokset suurimmasta pienimpään ja valita tulostaulun ensimmäisen rivin:
SELECT COUNT(*) c FROM Elokuvat GROUP BY vuosi ORDER BY c DESC LIMIT 1;
c
----------
2
Sijaluvut
Tarkastellaan taulua, jossa on pelaajia ja heidän tuloksiaan:
id nimi tulos
---------- ---------- ----------
1 Aapeli 45
2 Kaaleppi 115
3 Liisa 120
4 Maija 80
5 Uolevi 120
Tavoitteena on hakea rivit järjestyksessä tuloksen mukaan suurimmasta pienempään ja ilmoittaa lisäksi kunkin rivin sijaluku. Yksi tapa toteuttaa tämä on tehdä alikysely, joka laskee, monellako rivillä tulos on parempi, jolloin sija on yhtä suurempi kuin alikyselyn tulos:
SELECT
(SELECT COUNT(*) FROM Tulokset WHERE tulos > T.tulos)+1 sija, nimi, tulos
FROM
Tulokset T
ORDER BY
tulos DESC, nimi;
sija nimi tulos
---------- ---------- ----------
1 Liisa 120
1 Uolevi 120
3 Kaaleppi 115
4 Maija 80
5 Aapeli 45
Samalla idealla voidaan laskea sijaluvut myös niin, että jokaisella on eri sija ja yhtä suuren tuloksen tapauksessa aakkosjärjestys ratkaisee sijan:
SELECT
(SELECT COUNT(*) FROM Tulokset WHERE tulos > T.tulos OR (tulos = T.tulos AND nimi < T.nimi))+1 sija, nimi, tulos
FROM
Tulokset T
ORDER BY
tulos DESC, nimi;
sija nimi tulos
---------- ---------- ----------
1 Liisa 120
2 Uolevi 120
3 Kaaleppi 115
4 Maija 80
5 Aapeli 45
Vaihtoehtoinen tapa laskea sijalukuja on ikkunafunktio, jos käytetty tietokanta sallii sen. Esimerkiksi SQLiten uusissa versioissa ikkunafunktioiden RANK ja ROW_NUMBER avulla voidaan laskea vastaavat sijaluvut kuin äskeisissä esimerkeissä.
Listojen vertailu
Tarkastellaan taulua, johon on tallennettu listojen sisältö. Esimerkiksi seuraavassa taulussa lista 1 sisältää luvut [2, 4, 5], lista 2 sisältää luvut [3, 5] ja lista 3 sisältää luvut [2, 4, 5]:
id lista_id luku
---------- ---------- ----------
1 1 2
2 1 4
3 1 5
4 2 3
5 2 5
6 3 2
7 3 4
8 3 5
Seuraava kysely laskee jokaiselle listaparille, montako yhteistä tulosta niillä on:
SELECT
A.lista_id, B.lista_id, COUNT(*)
FROM
Listat A, Listat B
WHERE
A.luku=B.luku
GROUP BY
A.lista_id, B.lista_id;
lista_id lista_id COUNT(*)
---------- ---------- ----------
1 1 3
1 2 1
1 3 3
2 1 1
2 2 2
2 3 1
3 1 3
3 2 1
3 3 3
Tästä selviää, että esimerkiksi listoilla 1 ja 2 on yksi yhteinen luku (5) ja listoilla 1 ja 3 on kolme yhteistä lukua (2, 4, 5). Tällaista kyselyä laajentamalla voidaan vaikkapa vertailla, onko kahdella listalla täysin sama sisältö. Näin on silloin, kun listoilla on yhtä monta lukua ja yhteisten lukujen määrä on yhtä suuri kuin yksittäisen listan lukujen määrä.
5. Tietokannat ohjelmoinnissa
Tietokannan käyttäminen
Python-kielen standardikirjastossa on moduuli sqlite3, jonka avulla voidaan käyttää SQLite-tietokantaa. Seuraava koodi on pohja tietokannan käyttämiselle:
import sqlite3
db = sqlite3.connect("testi.db")
db.isolation_level = None
# tietokantakomennot
Koodi luo olion db, jonka kautta voidaan käyttää tiedostossa testi.db olevaa tietokantaa. Jos tiedostoa ei ole valmiina olemassa, tiedosto luodaan ja tietokanta on aluksi tyhjä.
Koodi myös määrittelee, että isolation_level on None, mikä tarkoittaa, että kun tietokantaan tehdään muutoksia, ne tulevat voimaan välittömästi samaan tapaan kuin SQLite-tulkissa.
Komentojen suoritus
Metodi execute suorittaa halutun SQL-komennon tietokannassa. Esimerkiksi seuraavat komennot luovat taulun Tuotteet ja lisäävät sinne kolme riviä:
db.execute("CREATE TABLE Tuotteet (id INTEGER PRIMARY KEY, nimi TEXT, hinta INTEGER)")
db.execute("INSERT INTO Tuotteet (nimi, hinta) VALUES ('selleri', 5)")
db.execute("INSERT INTO Tuotteet (nimi, hinta) VALUES ('nauris', 8)")
db.execute("INSERT INTO Tuotteet (nimi, hinta) VALUES ('lanttu', 4)")
Samalla tavalla voidaan myös hakea tietoa tietokannasta. Metodi fetchall antaa kyselyn tulokset listana, jossa jokaista tulostaulun riviä vastaa tuple:
tuotteet = db.execute("SELECT nimi, hinta FROM Tuotteet").fetchall()
print(tuotteet)
[('selleri', 5), ('nauris', 8), ('lanttu', 4)]
Metodi fetchone puolestaan palauttaa ensimmäisen tulosrivin tuplena. Tämä metodi on erityisen hyödyllinen kyselyissä, jotka palauttavat aina yhden rivin:
hinta = db.execute("SELECT MAX(hinta) FROM Tuotteet").fetchone()
print(hinta)
(8,)
Parametrit
Seuraava koodi kysyy käyttäjältä tuotteen nimeä ja ilmoittaa sitten tuotteen hinnan tai tiedon siitä, että tuotetta ei ole tietokannassa.
nimi = input("Tuotteen nimi: ")
hinta = db.execute("SELECT hinta FROM Tuotteet WHERE nimi=?", [nimi]).fetchone()
if hinta:
print("Hinta on", hinta[0])
else:
print("Ei löytynyt")
Tässä käyttäjän antama tieto yhdistetään kyselyyn parametrina: kyselyssä tiedon kohdalla on merkki ? ja sen kohdalle tuleva arvo annetaan listassa. Esimerkiksi jos käyttäjä antaa nimen nauris, kyselystä tulee SELECT hinta FROM Tuotteet WHERE nimi='nauris'. Tästä näkee, että merkkijonon tapauksessa '-merkit lisätään automaattisesti oikealla tavalla.
Seuraava koodi puolestaan lisää uuden tuotteen tietokantaan:
nimi = input("Tuotteen nimi: ")
hinta = input("Tuotteen hinta: ")
db.execute("INSERT INTO Tuotteet (nimi, hinta) VALUES (?, ?)", [nimi, hinta])
Kun parametreja on useita, ne tulevat listan arvoista samassa järjestyksessä.
Parametrien avulla tieto liitetään varmasti oikealla tavalla SQL-komennon osaksi. Esimerkiksi jos tuotteen nimi on Pepe's Drink, nimessä esiintyy '-merkki ja oikea tapa ilmoittaa nimi komennossa on 'Pepe\'s Drink'. Kun tieto annetaan parametrina, tämä muutos tehdään automaattisesti. Erityisesti web-sovelluksissa parametrien käyttäminen estää myös SQL-injektion, jossa pahantahtoinen käyttäjä yrittää muuttaa komennon rakennetta. Tutustumme aiheeseen tarkemmin kurssilla Tietokantasovellus.
Virheenkäsittely
Tietokannassa suoritettava komento saattaa epäonnistua. Esimerkiksi seuraava komento epäonnistuu, jos taulu Tuotteet on jo olemassa:
db.execute("CREATE TABLE Tuotteet (id INTEGER PRIMARY KEY, nimi TEXT, hinta INTEGER)")
Tällöin ohjelman suoritus päättyy seuraavaan virheeseen:
Traceback (most recent call last):
File "testi.py", line 6, in <module>
db.execute("CREATE TABLE Tuotteet (id INTEGER PRIMARY KEY, nimi TEXT, hinta INTEGER)")
sqlite3.OperationalError: table Tuotteet already exists
Virhe voidaan käsitellä myös Python-koodin puolella vaikkapa näin:
try:
db.execute("CREATE TABLE Tuotteet (id INTEGER PRIMARY KEY, nimi TEXT, hinta INTEGER)")
except:
print("Taulua ei voitu luoda")
Tällöin ohjelman suoritus jatkuu eteenpäin eikä pääty virheeseen.
Lisätyn rivin id-numero
Seuraava koodi ilmoittaa tietokantaan lisätyn rivin id-numeron:
tulos = db.execute("INSERT INTO Tuotteet (nimi, hinta) VALUES ('lanttu', 4)")
print(tulos.lastrowid)
Tästä on hyötyä, jos tietokantaan lisätään tämän jälkeen muita rivejä, joka viittaavat ensin lisättyyn riviin.
Käyttöliittymä
Seuraava ohjelma toteuttaa käyttöliittymän, jonka avulla käyttäjä voi lisätä tietokantaan tuotteita, hakea tuotteen hinnan tai poistua ohjelmasta. Ohjelma olettaa, että tiedostossa testi.db on valmiina olemassa taulu Tuotteet.
import sqlite3
db = sqlite3.connect("testi.db")
db.isolation_level = None
print("1 - Lisää uusi tuote")
print("2 - Hae tuotteen hinta")
print("3 - Sulje ohjelma")
while True:
komento = input("Anna komento: ")
if komento == "1":
nimi = input("Tuotteen nimi: ")
hinta = input("Tuotteen hinta: ")
db.execute("INSERT INTO Tuotteet (nimi, hinta) VALUES (?,?)", [nimi, hinta])
if komento == "2":
nimi = input("Tuotteen nimi: ")
hinta = db.execute("SELECT hinta FROM Tuotteet WHERE nimi=?", [nimi]).fetchone()
if hinta:
print("Hinta on", hinta[0])
else:
print("Ei löytynyt")
if komento == "3":
break
Ohjelman suoritus voi näyttää seuraavalta:
1 - Lisää uusi tuote
2 - Hae tuotteen hinta
3 - Sulje ohjelma
Anna komento: 2
Tuotteen nimi: selleri
Hinta on 5
Anna komento: 2
Tuotteen nimi: palsternakka
Ei löytynyt
Anna komento: 1
Tuotteen nimi: palsternakka
Tuotteen hinta: 9
Anna komento: 2
Tuotteen nimi: palsternakka
Hinta on 9
Anna komento: 3
Koodin rakenne paremmaksi
Usein pidetään hyvänä, että tietokannan käsittely ja käyttöliittymän toteutus ovat toisistaan erillään ohjelmassa. Seuraava koodi toteuttaa tämän niin, että moduuli tuotteet.py käsittelee tietokantaa ja moduuli main.py on pääohjelma, joka näyttää käyttöliittymän.
tuotteet.py
import sqlite3
db = sqlite3.connect("testi.db")
db.isolation_level = None
def lisaa_tuote(nimi, hinta):
db.execute("INSERT INTO Tuotteet (nimi, hinta) VALUES (?,?)", [nimi, hinta])
def hae_hinta(nimi):
hinta = db.execute("SELECT hinta FROM Tuotteet WHERE nimi=?", [nimi]).fetchone()
if hinta:
return hinta[0]
else:
return None
main.py
import tuotteet
print("1 - Lisää uusi tuote")
print("2 - Hae tuotteen hinta")
print("3 - Sulje ohjelma")
while True:
komento = input("Anna komento: ")
if komento == "1":
nimi = input("Tuotteen nimi: ")
hinta = input("Tuotteen hinta: ")
tuotteet.lisaa_tuote(nimi, hinta)
if komento == "2":
nimi = input("Tuotteen nimi: ")
hinta = tuotteet.hae_hinta(nimi)
if hinta:
print("Hinta on", hinta)
else:
print("Ei löytynyt")
if komento == "3":
break
Tällaisessa toteutuksessa käyttöliittymässä ei näy mitään siitä, että tiedot tallennetaan nimenomaan SQLite-tietokantaan, vaan tallennustapaa voisi periaatteessa muuttaa ilman, että käyttöliittymään tulisi mitään muutoksia.
Laajemmassa sovelluksessa olisi mielekästä jakaa tietokannan käsittely useampaan tiedostoon. Tällaisia sovelluksia tehdään myöhemmillä tietojenkäsittelytieteen kursseilla.
Mitä tehdä missäkin
Tietokannan ja koodin puolella voi usein tehdä samantapaisia asioita. Esimerkiksi seuraavassa on kaksi tapaa etsiä kalleimman tuotteen hinta tietokannasta:
kallein = db.execute("SELECT MAX(hinta) FROM Tuotteet").fetchone()
hinnat = db.execute("SELECT hinta FROM Tuotteet").fetchall()
kallein = max(hinnat)
Ensimmäisessä tavassa haetaan kallein hinta tietokannan puolella SQL:n MAX-funktiolla. Toisessa tavassa puolestaan haetaan tietokannasta kaikkien tuotteiden hinnat listaan ja etsitään sitten koodin puolella listan kallein hinta Pythonin max-funktiolla.
Näistä kahdesta tavasta ensimmäinen tapa on selkeästi parempi: ei ole hyvä hakea turhaa tietoa koodin puolelle ja tehdä käsittelyä, jonka voi tehdä helposti myös tietokannassa.
Erityisesti kannattaa välttää tilannetta, jossa suoritetaan turhaan useita SQL-komentoja, vaikka vain yksi komento riittäisi. Esimerkiksi seuraavassa on huono tapa hakea tietokannasta jokaisen opettajan nimi ja kurssien määrä:
opettajat = db.execute("SELECT id, nimi FROM Opettajat").fetchall()
for opettaja in opettajat:
maara = db.execute("SELECT COUNT(*) FROM Kurssit WHERE opettaja_id=?", [opettaja[0]]).fetchone()
print(opettaja[1], maara[0])
Koodi hakee ensin listaan kunkin opettajan id-numeron ja nimen ja sitten jokaisesta opettajasta erikseen niiden kurssien määrän, joita kyseinen opettaja opettaa. Koodi on kyllä toimiva mutta se tekee valtavasti turhaa työtä hakiessaan jokaisen tiedon erikseen. Parempi ratkaisu on muodostaa yksi kysely, joka hakee suoraan kaiken tarvittavan:
tiedot = db.execute("SELECT O.nimi, COUNT(*) FROM Opettajat O LEFT JOIN Kurssit K ON O.id = K.opettaja_id GROUP BY O.id").fetchall()
for rivi in tiedot:
print(rivi[0], rivi[1])
Tuloksena oleva kysely on monimutkaisempi, mutta sen avulla tietokantajärjestelmä voi optimoida kokonaisuutena halutun tiedon hakemisen ja toimittaa tiedon mahdollisimman tehokkaasti koodille.
Kuitenkaan tietokannan puolella ei kannata tehdä kaikkea, mikä on teoriassa mahdollista. Tästä esimerkkinä on seuraava koodi, joka hakee tietokannasta tuloslistan, jossa pelaajat on järjestettynä pistemäärän ja nimen mukaan. Tulostuksessa pelaajista näytetään myös sija (1, 2, 3, jne.) listalla.
lista = db.execute("SELECT nimi, pisteet FROM Tulokset ORDER BY pisteet DESC, nimi").fetchall()
sija = 1
for tulos in lista:
print(sija, tulos[0], tulos[1])
sija += 1
Tässä tapauksessa pelaajien sijat lasketaan koodin puolella muuttujan sija avulla. Olisi mahdollista laatia monimutkainen SQL-kysely, jonka tulostaulussa on myös sijat, mutta tässä tapauksessa siitä tuskin olisi hyötyä, koska sijat voi laskea helposti ja tehokkaasti myös koodin puolella. Tällaisen kyselyn laatiminen on kuitenkin kiinnostava teoreettinen haaste, erityisesti käyttämättä ikkunafunktioita.
6. Tietokannan suunnittelu
Suunnittelun periaatteet
Tietokannan suunnittelussa meidän tulee päättää tietokannan rakenne: mitä tauluja tietokannassa on sekä mitä sarakkeita kussakin taulussa on. Tähän on sinänsä suuri määrä mahdollisuuksia, mutta tuntemalla muutaman periaatteen pääsee pitkälle.
Hyvä tavoite suunnittelussa on, että tuloksena olevaa tietokantaa on mukavaa käyttää SQL-kielen avulla. Tietokannan rakenteen tulisi olla sellainen, että pystymme hakemaan ja muuttamaan tietoa näppärästi SQL-komennoilla.
Tietokannan suunnittelun periaatteet ovat hyödyllisiä ja johtavat usein toimiviin ratkaisuihin. Kuitenkin aina kannattaa miettiä, mikä periaatteissa on taustalla ja milloin kannattaa mahdollisesti tehdä toisin. Tavoitteen tulisi olla aina se, että tietokanta on käyttötarkoitukseen sopiva, eikä että noudatetaan periaatteita ilman omaa ajattelua.
Taulu vs. luokka
Tietokannan taulu ja olio-ohjelmoinnin luokka ovat samantapaisia käsitteitä. Molemmissa on kyse siitä, että määrittelemme tiedon tyypin. Taulun sarakkeet muistuttavat luokan attribuutteja, ja taulun rivi vastaa luokasta luotua oliota.
Esimerkiksi seuraava SQL-komento ja Python-koodi vastaavat toisiaan:
CREATE TABLE Elokuvat (
id INTEGER PRIMARY KEY,
nimi TEXT,
vuosi INTEGER
);
class Elokuva:
def __init__(self, nimi : str, vuosi : int):
self.nimi = nimi
self.vuosi = vuosi
Huomaa, että luokassa ei ole attribuuttia id, koska ohjelmoinnissa olioilla on viittaukset, joiden avulla ne voidaan yksilöidä.
Rivin lisääminen tietokannan tauluun vastaa uuden olion muodostamista luokasta. Esimerkiksi seuraavat komennot vastaavat toisiaan:
INSERT INTO Elokuvat (nimi,vuosi) VALUES ('Lumikki',1937);
INSERT INTO Elokuvat (nimi,vuosi) VALUES ('Fantasia',1940);
INSERT INTO Elokuvat (nimi,vuosi) VALUES ('Pinocchio',1940);
a = Elokuva("Lumikki",1937)
b = Elokuva("Fantasia",1940)
c = Elokuva("Pinocchio",1940)
Yksi vai useita tauluja?
Ohjelmoinnissa kaikki saman tyyppiset oliot perustuvat samaan luokkaan, ja vastaavasti periaatteena tietokannan suunnittelussa on, että kaikki saman tyyppiset rivit ovat yhdessä taulussa. Tämän ansiosta voimme käsitellä rivejä kätevästi SQL-komennoilla.
Esimerkiksi jos tietokannassa on elokuvia, hyvä ratkaisu on tallentaa kaikki elokuvat samaan tauluun Elokuvat:
id nimi vuosi
---------- ---------- ----------
1 Lumikki 1937
2 Fantasia 1940
3 Pinocchio 1940
4 Dumbo 1941
5 Bambi 1942
Tästä taulusta voimme hakea esimerkiksi vuoden 1940 elokuvat näin:
SELECT nimi FROM Elokuvat WHERE vuosi=1940;
Mutta mitä kävisi, jos jakaisimmekin elokuvat moneen tauluun? Esimerkiksi voisimme jakaa elokuvat tauluihin vuosien mukaan. Tällöin taulussa Elokuvat1940 olisi vuoden 1940 elokuvat, ja voisimme hakea ne näin:
SELECT nimi FROM Elokuvat1940;
Tällainen ratkaisu toimii niin kauan, kuin haluamme hakea vain tietyn vuoden elokuvia. Kuitenkin tietokanta muuttuu vaikeakäyttöiseksi heti, jos haluamme tehdä jotain muita hakuja. Esimerkiksi jos haluamme hakea kaikki elokuvat vuosilta 1940–1950, tarvitsemme useita kyselyjä:
SELECT nimi FROM Elokuvat1940;
SELECT nimi FROM Elokuvat1941;
SELECT nimi FROM Elokuvat1942;
...
SELECT nimi FROM Elokuvat1950;
Kuitenkin kun elokuvat ovat samassa taulussa, niin selviämme yhdellä kyselyllä:
SELECT nimi FROM Elokuvat WHERE vuosi BETWEEN 1940 AND 1950;
Kun elokuvat ovat yhdessä taulussa, pystymme käsittelemään niitä monipuolisesti yksittäisillä SQL-komennoilla, mikä ei olisi mahdollista, jos tauluja olisi useita.
Viittausten toteutus
Ohjelmoinnissa olion sisällä voi olla viittaus toiseen olioon, ja vastaavasti tietokannan taulun rivillä voi olla viittaus toiseen riviin. Kun jokaisella taulun rivillä on pääavaimena id-numero, riveihin on kätevää viitata muualta.
Yksi moneen -suhde
Tarkastellaan tilannetta, jossa tallennamme tietokantaan kursseja ja opettajia. Taulujen välillä on yksi moneen -suhde: jokaisella kurssilla on yksi opettaja, kun taas yhdellä opettajalla voi olla monta kurssia. Pythonissa voisimme luoda luokat näin:
class Opettaja:
def __init__(self, nimi : str):
self.nimi = nimi
class Kurssi:
def __init__(self, nimi : str, opettaja : Opettaja):
self.nimi = nimi
self.opettaja = opettaja
Vastaavasti voimme luoda tietokannan taulut näin:
CREATE TABLE Opettajat (
id INTEGER PRIMARY KEY,
nimi TEXT
);
CREATE TABLE Kurssit (
id INTEGER PRIMARY KEY,
nimi TEXT,
opettaja_id INTEGER REFERENCES Opettajat
);
Taulussa Kurssit sarake opettaja_id viittaa tauluun Opettajat, eli siinä on jonkin opettajan id-numero. Ilmaisemme viittauksen REFERENCES-määreellä, joka kertoo, että sarakkeessa oleva kokonaisluku viittaa nimenomaan tauluun Opettajat.
Voisimme laittaa tauluihin tietoa vaikkapa seuraavasti:
INSERT INTO Opettajat (nimi) VALUES ('Kaila');
INSERT INTO Opettajat (nimi) VALUES ('Kivinen');
INSERT INTO Opettajat (nimi) VALUES ('Laaksonen');
INSERT INTO Kurssit (nimi, opettaja_id) VALUES ('Ohjelmoinnin perusteet',1);
INSERT INTO Kurssit (nimi, opettaja_id) VALUES ('Ohjelmoinnin jatkokurssi',1);
INSERT INTO Kurssit (nimi, opettaja_id) VALUES ('Tietokantojen perusteet',3);
INSERT INTO Kurssit (nimi, opettaja_id) VALUES ('Tietorakenteet ja algoritmit',2);
Monta moneen -suhde
Tarkastellaan sitten tilannetta, jossa useampi opettaja voi järjestää kurssin yhteisesti. Tällöin kyseessä on monta moneen -suhde, koska kurssilla voi olla monta opettajaa ja opettajalla voi olla monta kurssia.
Pythonissa voisimme toteuttaa tämän muutoksen helposti muuttamalla luokkaa Kurssi niin, että siinä on yhden opettajan sijasta lista opettajista:
class Kurssi:
def __init__(self, nimi : str):
self.nimi = nimi
self.opettajat = []
def lisaa_opettaja(self, opettaja : Opettaja):
self.opettajat.append(opettaja)
Tietokannoissa tilanne on kuitenkin toinen, koska emme voi tallentaa järkevästi taulun sarakkeeseen listaa viittauksista. Tämän sijasta meidän täytyy luoda uusi taulu viittauksille:
CREATE TABLE Opettajat (
id INTEGER PRIMARY KEY,
nimi TEXT
);
CREATE TABLE Kurssit (
id INTEGER PRIMARY KEY,
nimi TEXT
);
CREATE TABLE KurssinOpettajat (
kurssi_id INTEGER REFERENCES Kurssit,
opettaja_id INTEGER REFERENCES Opettaja
);
Muutoksena on, että taulussa Kurssit ei ole enää viittausta tauluun Opettajat, mutta sen sijaan tietokannassa on uusi taulu KurssinOpettajat, joka viittaa kumpaankin tauluun. Jokainen rivi tässä rivissä kuvaa yhden suhteen muotoa “kurssilla x opettaa opettaja y”.
Esimerkiksi voisimme ilmaista näin, että kurssilla on kaksi opettajaa:
INSERT INTO Opettajat (nimi) VALUES ('Kivinen');
INSERT INTO Opettajat (nimi) VALUES ('Laaksonen');
INSERT INTO Kurssit (nimi) VALUES ('Tietorakenteet ja algoritmit');
INSERT INTO KurssinOpettajat VALUES (1,1);
INSERT INTO KurssinOpettajat VALUES (1,2);
Huomaa, että voisimme käyttää tätä ratkaisua myös aiemmassa tilanteessa, jossa kurssilla on aina tasan yksi opettaja, joskin tietokannassa olisi silloin tavallaan turha taulu.
Tiedon atomisuus
Periaate: Tietokannan taulun jokaisessa sarakkeessa on yksittäinen eli atominen tieto, kuten yksi luku tai yksi merkkijono. Sarakkeessa ei saa olla listaa tiedoista.
Tämä periaate helpottaa tietokannan käsittelyä SQL-komentojen avulla: kun jokainen tieto on omassa sarakkeessaan, niin pystymme viittaamaan tietoon kätevästi komennoissa.
Kun tietokantaan halutaan tallentaa listoja, luodaan uusi taulu, jossa jokainen rivi on jonkin listan yksittäinen alkio, kuten äskeinen taulu KurssinOpettajat. Mutta miksi emme voisi vain tallentaa listaa yhteen sarakkeeseen? Seuraava esimerkki selventää asiaa.
Esimerkki
Vaihe 1
Haluamme tallentaa tietokantaan opiskelijoiden tenttituloksia. Tentissä on neljä tehtävää, joista voi saada 0–6 pistettä. Voisimme koettaa tallentaa pisteet näin:
id opiskelija_id pisteet
---------- ------------- ----------
1 1 6,5,1,4
2 2 3,6,6,6
3 3 6,4,0,6
Ideana on, että sarakkeessa pisteet on merkkijono, jossa on lista pisteistä pilkuilla erotettuina. Tämä ratkaisu kuitenkin rikkoo periaatetta, että jokaisessa sarakkeessa on yksittäinen tieto. Mitä vikaa ratkaisussa on?
Ratkaisun ongelmana on, että meidän on vaivalloista koettaa päästä pisteisiin käsiksi SQL-komennoissa, koska pisteet ovat merkkijonon sisällä. Esimerkiksi jos haluamme laskea jokaisen opiskelijan yhteispisteet, tarvitsemme seuraavan tapaisen kyselyn:
SELECT opiskelija_id, SUBSTR(pisteet,1,1)+
SUBSTR(pisteet,3,1)+
SUBSTR(pisteet,5,1)+
SUBSTR(pisteet,7,1) FROM Tulokset;
Tässä funktio SUBSTR erottaa merkkijonosta tietyssä kohdassa olevan osajonon. Kysely on kuitenkin hankala ja lisäksi toimii vain, kun pisteitä on tasan neljä ja ne ovat yksinumeroisia. Tarvitsemme paremman tavan tallentaa pisteet.
Vaihe 2
Seuraavassa taulussa pisteille on neljä saraketta, jolloin voimme käsitellä niitä yksitellen:
id opiskelija_id pisteet1 pisteet2 pisteet3 pisteet4
---------- ------------- ---------- ---------- ---------- ----------
1 1 6 5 1 4
2 2 3 6 6 6
3 3 6 4 0 6
Tämän ansiosta saamme jo toteutettua kyselyn mukavammin:
SELECT opiskelija_id, pisteet1+pisteet2+pisteet3+pisteet4 FROM Tulokset;
Tämä ratkaisu on selkeästi parempaan suuntaan, mutta siinä on edelleen ongelmia. Vaikka pisteet ovat eri sarakkeissa, oletuksena on edelleen, että tehtäviä on tasan neljä. Jos tehtävien määrä muuttuu, joudumme muuttamaan taulun rakennetta ja kaikkia pisteisiin liittyviä SQL-komentoja, mikä ei ole hyvä tilanne.
Vaihe 3
Kun haluamme tallentaa listan tietokantaan, hyvä ratkaisu on tallentaa jokainen listan alkio omalle rivilleen. Tämän esimerkin tapauksessa voimme luoda taulun, jonka jokainen rivi ilmaisee tietyn opiskelijan pisteet tietyssä tehtävässä:
id opiskelija_id tehtava_id pisteet
---------- ------------- ---------- ----------
1 1 1 6
2 1 2 5
3 1 3 1
4 1 4 4
5 2 1 3
6 2 2 6
7 2 3 6
8 2 4 6
9 3 1 6
10 3 2 4
11 3 3 0
12 3 4 6
Nyt voimme hakea kunkin opiskelijan yhteispisteet näin:
SELECT opiskelija_id, SUM(pisteet) FROM Tulokset GROUP BY opiskelija_id;
Tämä on yleiskäyttöinen kysely eli se toimii yhtä hyvin riippumatta tehtävien määrästä. Pystymme hyödyntämään summan laskemisessa funktiota SUM sen sijaan, että meidän tulisi luetella kaikki tehtävät itse.
Huomaa, että muutoksen seurauksena taulun rivien määrä kasvoi selvästi. Tätä ei kannata kuitenkaan hätkähtää: tietokantajärjestelmät on toteutettu niin, että ne toimivat hyvin, vaikka taulussa olisi paljon rivejä.
Mikä on atomista tietoa?
Atomisen tiedon käsite ei ole hyvin määritelty. Selkeästi lista ei ole atominen tieto, mutta onko sitten vaikka merkkijonokaan, jossa on useita sanoja?
Tarkastellaan esimerkkinä tilannetta, jossa taulun sarakkeessa on käyttäjän nimi. Onko tämä huonoa suunnittelua, koska samassa sarakkeessa on etu- ja sukunimi?
id nimi
---------- --------------
1 Anna Virtanen
2 Maija Korhonen
3 Pasi Lahtinen
Voisimme myös tallentaa etu- ja sukunimen erikseen näin:
id etunimi sukunimi
---------- ---------- ----------
1 Anna Virtanen
2 Maija Korhonen
3 Pasi Lahtinen
Riippuu tilanteesta, kumpi taulu on parempi. Jos järjestelmässä on erityisesti tarvetta etsiä tietoa etu- tai sukunimen perusteella (esimerkiksi etsiä kaikki käyttäjät, joiden etunimi on Anna), jälkimmäinen taulu on parempi. Kuitenkaan usein ei ole näin eikä ole mitään pahaa tallentaa samaan sarakkeeseen etu- ja sukunimi.
Vastaavasti jos tietokantaan tallennetaan käyttäjän lähettämä viesti, siinä voi olla monia sanoja eli tavallaan viesti on lista sanoja, mutta on silti hyvä ratkaisu tallentaa koko viesti yhteen sarakkeeseen, koska viestiä käsitellään tietokannassa yhtenä kokonaisuutena. Olisi hyvin huono ratkaisu jakaa “atomisesti” viestin sanat omiin sarakkeisiin.
Kannattaakin ajatella asiaa niin, että jos jotain tietoa on tarvetta käsitellä erillisenä SQL-komennoissa, niin se on atominen tieto, jonka tulee olla omassa sarakkeessa. Jos taas tietoon ei viitata SQL-komennoissa, se voi olla sarakkeessa osana laajempaa kokonaisuutta.
Toisteinen tieto
Periaate: Jokainen tieto on tasan yhdessä paikassa tietokannassa. Tietokannassa ei ole tietoa, jonka voi laskea tai päätellä tietokannan muun sisällön perusteella.
Tätä periaatetta seuraamalla tietokannan sisällön päivittäminen on helppoa, koska päivitys riittää tehdä yhteen paikkaan eikä se vaikuta tietokannan muihin osiin.
Esimerkki 1
Tallennamme järjestelmään käyttäjien lähettämiä viestejä seuraavasti tauluun Viestit:
id kayttaja viesti
---------- ---------- --------------
1 Anna123 Missä olet?
2 Joulupukki Bussissa vielä
3 Anna123 Meneekö kauan?
4 Joulupukki 5 min
Tämä on muuten toimiva ratkaisu, mutta tietokannan sisältöä on hankalaa päivittää, jos käyttäjä päättää vaihtaa nimeään. Esimerkiksi jos Anna123 haluaa muuttaa nimeään, muutos täytyy tehdä jokaiseen viestiin, jonka hän on lähettänyt.
Parempi ratkaisu on toteuttaa tietokanta niin, että käyttäjän nimi on vain yhdessä paikassa. Luonteva paikka tälle on taulu Kayttajat, joka sisältää käyttäjät:
id nimi
---------- ----------
1 Anna123
2 Joulupukki
Muissa tauluissa on vain viitteenä käyttäjän id-numero, joka on muuttumaton tieto. Esimerkiksi taulu Viestit näyttää nyt tältä:
id kayttaja_id viesti
---------- ----------- --------------
1 1 Missä olet?
2 2 Bussissa vielä
3 1 Meneekö kauan?
4 2 5 min
Tämän jälkeen käyttäjän nimen muuttaminen on helppoa, koska muutos riittää tehdä taulun Kayttajat yhteen riviin ja muutos päivittyy heti kaikkialle, koska muissa tauluissa viitataan edelleen oikeaan riviin.
Tämä monimutkaistaa kyselyjä, koska meidän täytyy hakea tietoa useista tauluista, mutta ratkaisu on kuitenkin kokonaisuuden kannalta hyvä.
Vieläkin toisteisuutta?
Äskeisestä muutoksesta huolimatta tietokannassa saattaa esiintyä edelleen toisteisuutta. Esimerkiksi seuraavassa tilanteessa käyttäjät lähettävät samanlaisen viestin “Hei!”. Pitäisikö tietokannan rakennetta parantaa?
id kayttaja_id viesti
---------- ----------- --------------
1 1 Hei!
2 2 Hei!
Tässä tapauksessa ei olisi hyvä idea toteuttaa tietokantaa niin, että jos kaksi käyttäjää lähettää saman sisältöisen viestin, viestin sisältö tallennetaan vain yhteen paikkaan.
Vaikka viesteissä on sama sisältö, ne ovat erillisiä viestejä, joiden ei ole tarkoitus viitata samaan asiaan. Jos käyttäjä 1 muuttaa viestin sisältöä, muutoksen ei tule heijastua käyttäjän 2 viestiin, vaikka siinä sattuu olemaan tällä hetkellä sama sisältö.
Esimerkki 2
Tallennamme tietokantaan tietoa opiskelijoiden suorituksista. Tietokannasta voidaan kysyä, montako opintopistettä opiskelija on suorittanut.
Seuraavassa tietokannassa jokaisen opiskelijan yhteyteen on tallennettu tieto, montako opintopistettä hän on suorittanut. Taulun Opiskelijat sisältönä on:
id nimi op
---------- ---------- ----------
1 Maija 20
2 Uolevi 10
Taulussa Suoritukset puolestaan on seuraavat rivit:
id opiskelija_id kurssi_id op
---------- ------------- ---------- ----------
1 1 1 5
2 1 2 5
3 1 4 10
4 2 1 5
5 2 3 5
Tämän ansiosta on helppoa hakea opiskelijan opintopisteiden yhteismäärä:
SELECT op FROM Opiskelijat WHERE nimi='Maija';
Kuitenkin tietokannassa on toisteista tietoa: taulun Opiskelijat sarakkeen op sisältö voidaan laskea taulun Suoritukset avulla. Ongelmana on, että jos lisäämme tai poistamme suorituksen, niin joudumme tekemään muutoksen kahteen eri tauluun. Jos muutos unohtuu tehdä tai epäonnistuu, tietokantaan tulee ristiriitaista tietoa.
Pääsemme eroon toisteisesta tiedosta poistamalla sarakkeen op taulusta Opiskelijat:
id nimi
---------- ----------
1 Maija
2 Uolevi
Tämän muutoksen seurauksena on vaikeampaa selvittää opiskelijan opintopisteet, koska meidän täytyy laskea tieto suorituksista lähtien:
SELECT
SUM(S.op)
FROM
Suoritukset S, Opiskelijat O
WHERE
S.opiskelija_id=O.id AND O.nimi='Maija';
Tämä on kuitenkin kokonaisuutena hyvä muutos, koska nyt voimme huoletta muutella suorituksia ja luottaa siihen, että saamme aina haettua oikean tiedon opiskelijan opintopisteistä.
Muutokset vs. kyselyt
Vaikka ihanteena on, että tietokannassa ei ole toisteista tietoa, joskus kuitenkin toisteista tietoa tarvitaan hakujen tehostamiseksi. Toisteinen tieto vaikeuttaa tietokannan muuttamista mutta helpottaa kyselyjen tekemistä.
Usein esiintyvä ilmiö tietojenkäsittelytieteessä on, että joudumme tasapainoilemaan sen kanssa, haluammeko muuttaa vai hakea tehokkaasti tietoa ja paljonko tilaa voimme käyttää. Tämä tulee tietokantojen lisäksi vastaan esimerkiksi algoritmien suunnittelussa.
Jos tietokannassa ei ole toisteista tietoa, muutokset ovat helppoja, koska jokainen tieto on vain yhdessä paikassa eli riittää muuttaa vain yhden taulun yhtä riviä. Myös hyvänä puolena tietokanta vie vähän tilaa. Toisaalta kyselyt voivat olla monimutkaisia ja hitaita, koska halutut tiedot pitää kerätä kasaan eri puolilta tietokantaa.
Kun sitten lisäämme toisteista tietoa, pystymme nopeuttamaan kyselyjä mutta toisaalta muutokset hidastuvat, koska muutettu tieto pitää päivittää useaan paikkaan. Samaan aikaan myös tietokannan tilankäyttö kasvaa toisteisen tiedon takia.
Ei ole mitään yleistä sääntöä, paljonko toisteista tietoa kannattaa lisätä, vaan tämä riippuu tietokannan sisällöstä ja halutuista kyselyistä. Yksi hyvä tapa on aloittaa tilanteesta, jossa toisteista tietoa ei ole, ja lisätä sitten toisteista tietoa tarvittaessa, jos osoittautuu, että kyselyt eivät muuten ole riittävän tehokkaita.
Suunnitteluesimerkki
Tarkastellaan lopuksi laajempaa esimerkkiä, jossa tavoitteemme on suunnitella tietokanta Facebookin kaltaista yhteisöpalvelua varten. Tietokannan tulee mahdollistaa seuraavat toiminnot:
- Käyttäjä voi kirjautua palveluun antamalla sähköpostiosoitteen ja salasanan.
- Käyttäjällä on oma sivu, johon hän voi lähettää päivityksiä.
- Käyttäjä voi lisätä profiiliinsa tietoa, kuten nimen, syntymäpäivän, asuinpaikan, jne.
- Käyttäjä voi ystävystyä muiden palvelun käyttäjien kanssa.
- Käyttäjä voi lähettää palveluun valokuvia ja valita yhden niistä profiilikuvaksi.
- Käyttäjät voivat tykätä ja kommentoida toistensa päivityksiä ja kuvia.
- Käyttäjät voivat lähettää toisilleen yksityisviestejä.
- Palvelussa on myös ylläpitäjiä, joilla on enemmän oikeuksia kuin muilla käyttäjillä.
Suunnittelun vaiheet
Tietokannan suunnittelu etenee yleensä pikkuhiljaa niin, että tietokantaan lisätään uusia tauluja ja sarakkeita aina, kun uusissa toiminnoissa on tarvetta niille.
Seuraavaksi näemme, miten esimerkkitietokanta rakentuu vaihe vaiheelta vaadittujen toimintojen perusteella.
Kirjautuminen palveluun
- Käyttäjä voi kirjautua palveluun antamalla sähköpostiosoitteen ja salasanan.
Tämä on hyvin tavallinen toiminto, josta on hyvä aloittaa tietokannan suunnittelu. Tarvitsemme taulun, jossa on käyttäjän tunnus (sähköpostiosoite) ja salasana:
CREATE TABLE Kayttajat (
id INTEGER PRIMARY KEY,
tunnus TEXT,
salasana TEXT
);
Päivitykset omalle sivulle
- Käyttäjällä on oma sivu, johon hän voi lähettää päivityksiä.
Tätä toimintoa varten tietokantaan täytyy pystyä tallentamaan käyttäjän päivityksiä. Hyvä ratkaisu on luoda taulu, joka sisältää kaikkien käyttäjien päivitykset id-numeron mukaan:
CREATE TABLE Paivitykset (
id INTEGER PRIMARY KEY,
kayttaja_id INTEGER REFERENCES Kayttajat,
viesti TEXT,
aika DATETIME
);
Huomaa, että tietokantaan ei tarvitse tallentaa tietoa käyttäjän sivusta. Jokaisella käyttäjällä on sivu, joka sisältää käyttäjän päivitykset, mutta sivuun itsessään ei liity tietoa.
Profiilin tiedot
- Käyttäjä voi lisätä profiiliinsa tietoa, kuten nimen, syntymäpäivän, asuinpaikan, jne.
Yksi tapa toteuttaa tämä toiminto olisi laajentaa taulua Kayttajat:
CREATE TABLE Kayttajat (
id INTEGER PRIMARY KEY,
tunnus TEXT,
salasana TEXT,
nimi TEXT,
syntymapaiva DATE,
asuinpaikka TEXT,
...
);
Tämä on sinänsä toimiva tapa, mutta tässä voi tulla ongelmaksi, että profiilissa voi olla paljon vaihtelevaa tietoa, jolloin tauluun Kayttajat tulee suuri määrä sarakkeita. Tämän vuoksi teemme toisenlaisen ratkaisun ja luomme uuden taulun KayttajanTiedot:
CREATE TABLE KayttajanTiedot (
id INTEGER PRIMARY KEY,
kayttaja_id INTEGER REFERENCES Kayttajat,
avain TEXT,
arvo TEXT
);
Nyt käyttäjän tietoja voidaan lisätä tähän tapaan:
INSERT INTO KayttajanTiedot (kayttaja_id, avain TEXT, arvo TEXT)
VALUES (1,'nimi','Maija Virtanen');
INSERT INTO KayttajanTiedot (kayttaja_id, avain TEXT, arvo TEXT)
VALUES (1,'syntymapaiva','2000-01-01');
INSERT INTO KayttajanTiedot (kayttaja_id, avain TEXT, arvo TEXT)
VALUES (1,'asuinpaikka','Helsinki');
Tämän ratkaisu ansiosta tietokannan rakenteessa ei tarvitse määritellä, mitä kaikkea tietoa profiiliin mahdollisesti voidaan tallentaa, mutta tiedot on tallettu kuitenkin erillisinä.
Ystävyyssuhteet
- Käyttäjä voi ystävystyä muiden palvelun käyttäjien kanssa.
Tietokannassa täytyy olla tieto siitä, ketkä käyttäjät ovat ystäviä keskenään. Tämä onnistuu luomalla uusi taulu ystävyyssuhteita varten:
CREATE TABLE Ystavat (
id INTEGER PRIMARY KEY,
kayttaja1_id REFERENCES Kayttajat,
kayttaja2_id REFERENCES Kayttajat
);
Tämä taulu viittaa kahdesti tauluun Kayttajat, koska ystävyyssuhde liittyy kahteen käyttäjään.
Valokuvien lisääminen
- Käyttäjä voi lähettää palveluun valokuvia ja valita yhden niistä profiilikuvaksi.
Valokuvien lisääminen voidaan toteuttaa samaan tapaan kuin päivitysten lisääminen:
CREATE TABLE Valokuvat (
id INTEGER PRIMARY KEY,
kayttaja_id INTEGER REFERENCES Kayttajat,
kuva DATA
);
Tässä ei oteta tarkemmin kantaa siihen, miten valokuva tallennetaan palvelimelle, vaan sarakkeen tyyppinä on vain DATA.
Entä kuinka toteutamme profiilikuvan valitsemisen? Tähän on monia mahdollisia tapoja: voisimme lisätä tiedon asiasta tauluun Kayttajat tai Valokuvat tai luoda uuden taulun, joka kertoo, mikä kuva on kenenkin käyttäjän profiilikuva.
Koska käyttäjällä on enintään yksi profiilikuva, uudelle taululle ei ole oikeastaan tarvetta. Päädymme lisäämään tiedon tauluun Kayttajat, koska jos tieto olisi taulussa Valokuvat, pitäisi jotenkin erikseen varmistaa, että usea kuva ei ole samaan aikaan profiilikuvana. Tämän seurauksena taulu Kayttajat muuttuu näin:
CREATE TABLE Kayttajat (
id INTEGER PRIMARY KEY,
tunnus TEXT,
salasana TEXT,
kuva_id INTEGER REFERENCES Valokuvat
);
Tykkäykset ja kommentit
- Käyttäjät voivat tykätä ja kommentoida toistensa päivityksiä ja kuvia.
Tämän toiminnon toteuttamiseen on monia mahdollisuuksia. Seuraavassa ratkaisussa taulu Tykkaykset sisältää kaikki tykkäykset ja taulu Kommentit sisältää kaikki kommentit.
CREATE TABLE Tykkaykset (
id INTEGER PRIMARY KEY,
kayttaja_id INTEGER REFERENCES Kayttajat,
paivitys_id INTEGER REFERENCES Paivitykset,
kuva_id INTEGER REFERENCES Valokuvat
);
CREATE TABLE Kommentit (
id INTEGER PRIMARY KEY,
kayttaja_id INTEGER REFERENCES Kayttajat,
paivitys_id INTEGER REFERENCES Paivitykset,
kuva_id INTEGER REFERENCES Valokuvat,
viesti TEXT
aika DATETIME
);
Ideana on, että jos tykkäys tai kommentti liittyy päivitykseen, niin sarake paivitys_id osoittaa päivitykseen ja sarake kuva_id on NULL. Vastaavasti jos tykkäys tai kommentti liittyy kuvaan, sarake paivitys_id on NULL ja sarake kuva_id osoittaa kuvaan.
Vaihtoehtoinen ratkaisu olisi luoda kahden taulun sijasta neljä taulua niin, että päivitysten ja kuvien tiedot ovat omissa tauluissaan. Tämän etuna olisi, että riveillä ei ole NULL-arvoja, mutta tämä toisaalta mutkistaisi tietokannan rakennetta.
Yksityisviestit
- Käyttäjät voivat lähettää toisilleen yksityisviestejä.
Tämän toiminnon saamme toteutettua samalla tavalla kuin ystävystymisen lisäämällä uuden taulun, joka viittaa kahteen käyttäjään.
CREATE TABLE Viestit (
id INTEGER PRIMARY KEY,
kayttaja1_id INTEGER REFERENCES Kayttajat,
kayttaja2_id INTEGER REFERENCES Kayttajat,
viesti TEXT,
aika DATETIME
);
Tässä tulkintana on, että käyttäjä 1 on viestin lähettäjä ja käyttäjä 2 on viestin vastaanottaja.
Ylläpitäjät
- Palvelussa on myös ylläpitäjiä, joilla on enemmän oikeuksia kuin muilla käyttäjillä.
Tämän toiminnon toteuttamiseen on periaatteessa kaksi vaihtoehtoa: kaikki käyttäjät (myös ylläpitäjät) ovat samassa taulussa tai ylläpitäjät ovat erillisessä taulussa.
Kokemus on osoittanut, että parempi ratkaisu on tallentaa kaikki käyttäjät samaan tauluun, koska käyttäjillä on kuitenkin yhteisiä toimintoja, joiden toteuttaminen olisi hankalaa, jos tietoa pitäisi etsiä eri tauluista riippuen käyttäjän asemasta. Käyttäjät voidaan tallentaa samaan tauluun, kun tauluun lisätään sarake, joka ilmaisee käyttäjän roolin.
CREATE TABLE Kayttajat (
id INTEGER PRIMARY KEY,
tunnus TEXT,
salasana TEXT,
kuva_id INTEGER REFERENCES Valokuvat,
yllapitaja BOOLEAN
);
Tietokannan kuvaaminen
Tietokannan rakenteen kuvaamiseen on kaksi tavallista tapaa: graafinen tietokantakaavio, joka esittää taulujen suhteet, sekä SQL-skeema, jossa on taulujen luontikomennot.
Tietokantakaavio
Tietokantakaavio on tietokannan graafinen esitys, jossa jokainen tietokannan taulu on laatikko, joka sisältää taulun nimen ja sarakkeet listana. Rivien viittaukset toisiinsa esitetään laatikoiden välisinä yhteyksinä.
Tietokantakaavion piirtämiseen on monia vähän erilaisia tapoja. Seuraava kaavio on luotu netissä olevalla työkalulla dbdiagram.io:
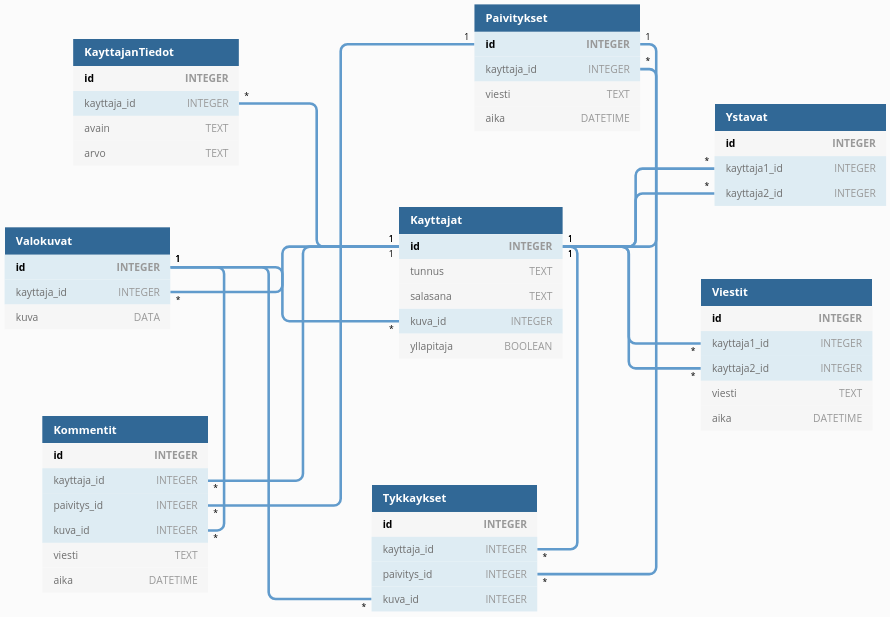
Tässä merkki 1 tarkoittaa, että sarakkeessa on eri arvo joka rivillä, ja merkki * puolestaan tarkoittaa, että sarakkeessa voi olla sama arvo usealla rivillä.
SQL-skeema
SQL-skeema sisältää CREATE TABLE -komennot, joiden avulla tietokanta voidaan muodostaa. Seuraava SQL-skeema vastaa tietokantaamme:
CREATE TABLE Kayttajat (
id INTEGER PRIMARY KEY,
tunnus TEXT,
salasana TEXT,
kuva_id INTEGER REFERENCES Valokuvat,
yllapitaja BOOLEAN
);
CREATE TABLE Paivitykset (
id INTEGER PRIMARY KEY,
kayttaja_id INTEGER REFERENCES Kayttajat,
viesti TEXT,
aika DATETIME
);
CREATE TABLE KayttajanTiedot (
id INTEGER PRIMARY KEY,
kayttaja_id INTEGER REFERENCES Kayttajat,
avain TEXT,
arvo TEXT
);
CREATE TABLE Ystavat (
id INTEGER PRIMARY KEY,
kayttaja1_id REFERENCES Kayttajat,
kayttaja2_id REFERENCES Kayttajat
);
CREATE TABLE Valokuvat (
id INTEGER PRIMARY KEY,
kayttaja_id INTEGER REFERENCES Kayttajat,
kuva DATA
);
CREATE TABLE Tykkaykset (
id INTEGER PRIMARY KEY,
kayttaja_id INTEGER REFERENCES Kayttajat,
paivitys_id INTEGER REFERENCES Paivitykset,
kuva_id INTEGER REFERENCES Valokuvat
);
CREATE TABLE Kommentit (
id INTEGER PRIMARY KEY,
kayttaja_id INTEGER REFERENCES Kayttajat,
paivitys_id INTEGER REFERENCES Paivitykset,
kuva_id INTEGER REFERENCES Valokuvat,
viesti TEXT
aika DATETIME
);
CREATE TABLE Viestit (
id INTEGER PRIMARY KEY,
kayttaja1_id INTEGER REFERENCES Kayttajat,
kayttaja2_id INTEGER REFERENCES Kayttajat,
viesti TEXT,
aika DATETIME
);
7. Tietokannan ominaisuudet
Tiedon eheys
Tiedon eheys viittaa siihen, että tietokannassa oleva tieto on paikkansa pitävää ja ristiriidatonta. Päävastuu tiedon laadusta on toki käyttäjällä tai sovelluksella, joka muuttaa tietokantaa, mutta myös tietokannan suunnittelija voi vaikuttaa asiaan lisäämällä tauluihin ehtoja, jotka tarkkailevat tietokantaan syötettävää tietoa.
Sarakkeiden ehdot
Voimme määrittää taulun luonnin yhteydessä sarakkeisiin liittyviä ehtoja, joita tietokantajärjestelmä valvoo tiedon lisäämisen ja muuttamisen yhteydessä. Näillä ehdoilla voi ohjata sitä, millaista tietoa tietokantaan ilmestyy. Tyypillisiä ehtoja ovat seuraavat:
UNIQUE
Ehto UNIQUE tarkoittaa, että kyseisessä sarakkeessa tulee olla eri arvo joka rivillä. Esimerkiksi seuraavassa taulussa vaatimuksena on, että joka tuotteella on eri nimi:
CREATE TABLE Tuotteet (id INTEGER PRIMARY KEY, nimi TEXT UNIQUE, hinta INTEGER);
Ehto UNIQUE voi kohdistua myös useampaan sarakkeeseen, jolloin se merkitään erikseen sarakkeiden jälkeen:
CREATE TABLE Tuotteet (id INTEGER PRIMARY KEY, nimi TEXT, hinta INTEGER, UNIQUE(nimi,hinta));
Tämä tarkoittaa, että taulussa ei voi olla kahta riviä, joilla on sama nimi ja sama hinta.
NOT NULL ja DEFAULT
Ehto NOT NULL tarkoittaa, että kyseisessä sarakkeessa ei saa olla arvoa NULL. Esimerkiksi seuraavassa taulussa tuotteen hinta ei saa olla tyhjä:
CREATE TABLE Tuotteet (id INTEGER PRIMARY KEY, nimi TEXT, hinta INTEGER NOT NULL);
Tähän liittyy myös määre DEFAULT, jonka seurauksena sarake saa tietyn oletusarvon, jos sille ei anneta arvoa rivin lisäämisessä. Esimerkiksi voimme määrittää oletusarvon 0 näin:
CREATE TABLE Tuotteet (id INTEGER PRIMARY KEY, nimi TEXT, hinta INTEGER DEFAULT 0);
CHECK
Yleisempi tapa luoda ehto on käyttää avainsanaa CHECK, jonka jälkeen voi kirjoittaa minkä tahansa ehtolausekkeen. Esimerkiksi seuraava komento luo taulun tuotteista, jossa rivin ehtona on hinta >= 0 eli hinta ei saa olla negatiivinen:
CREATE TABLE Tuotteet (id INTEGER PRIMARY KEY, nimi TEXT, hinta INTEGER, CHECK (hinta >= 0));
Ehtojen valvonta
Ehtojen hyötynä on, että tietokantajärjestelmä valvoo niitä ja kieltäytyy tekemästä lisäystä tai muutosta, joka rikkoisi ehdon. Seuraavassa on esimerkki tästä SQLitessä:
sqlite> CREATE TABLE Tuotteet (id INTEGER PRIMARY KEY, nimi TEXT, hinta INTEGER, CHECK (hinta >= 0));
sqlite> INSERT INTO Tuotteet(nimi,hinta) VALUES ('retiisi',4);
sqlite> INSERT INTO Tuotteet(nimi,hinta) VALUES ('selleri',7);
sqlite> INSERT INTO Tuotteet(nimi,hinta) VALUES ('nauris',-2);
Error: CHECK constraint failed: Tuotteet
sqlite> SELECT * FROM Tuotteet;
1|retiisi|4
2|selleri|7
sqlite> UPDATE Tuotteet SET hinta=-2 WHERE id=2;
Error: CHECK constraint failed: Tuotteet
Kun koetamme lisätä tauluun Tuotteet rivin, jossa hinta on negatiivinen, tämä rikkoo ehdon hinta >= 0 ja SQLite ei salli rivin lisäämistä vaan antaa virheen CHECK constraint failed: Tuotteet. Samalla tavalla käy, jos koetamme muuttaa olemassa olevan rivin sarakkeen hinnan negatiiviseksi jälkeenpäin.
Ehdot ohjelmoinnissa
Seuraava esimerkki näyttää, miten taulussa olevaa ehtoa voidaan hyödyntää ohjelmoinnissa. Haluamme, että tietokannan jokaisella tuotteella on eri nimi, minkä vuoksi sarakkeessa nimi on ehtona UNIQUE:
CREATE TABLE Tuotteet (id INTEGER PRIMARY KEY, nimi TEXT UNIQUE, hinta INTEGER);
Nyt tuotteen lisäämisen tietokantaan voi toteuttaa näin:
nimi = input("Anna nimi: ")
hinta = input("Anna hinta: ")
try:
db.execute("INSERT INTO Tuotteet (nimi, hinta) VALUES (?,?)", [nimi, hinta])
except:
print("Lisäys ei onnistunut")
Tässä tapauksessa komento INSERT epäonnistuu siinä tapauksessa, että taulussa on jo valmiina samanniminen tuote. Niinpä koodi voi yrittää lisätä tuotetta tutkimatta, onko tuote jo valmiina taulussa, ja jos tästä tulee virhe, tiedetään, että tuote oli valmiina.
Tämä on selkeästi parempi toteutus kuin tutkia koodissa ennen lisäämistä SELECT-kyselyllä, onko tuotetta jo tietokannassa, koska UNIQUE-ehdon avulla tietokanta pitää luotettavasti huolen asiasta ja koodiakin tarvitaan vähemmän. Jos taulussa ei olisi UNIQUE-ehtoa ja sovellus suorittaisi komennot SELECT ja INSERT, olisi mahdollista, että toinen tietokannan käyttäjä ehtisi lisätä välissä saman tuotteen tauluun, jolloin taulussa olisikin kaksi tuotetta samalla nimellä. Kuitenkaan UNIQUE-ehdon kanssa näin ei voi tapahtua mitenkään.
Viittausten ehdot
Voimme liittää myös tauluihin ehtoja, jotka pitävät huolen siitä, että tauluissa olevat viittaukset viittaavat todellisiin riveihin. Tämä tapahtuu luomalla viiteavain (foreign key), joka ilmaisee, mihin taulussa oleva rivi viittaa.
Tarkastellaan esimerkkinä seuraavia tauluja:
CREATE TABLE Opettajat (id INTEGER PRIMARY KEY, nimi TEXT);
CREATE TABLE Kurssit (id INTEGER PRIMARY KEY, nimi TEXT, opettaja_id INTEGER);
Tässä tarkoituksena on, että taulun Kurssit sarake opettaja_id viittaa taulun Opettajat sarakkeeseen id, mutta tietokannan käyttäjä voi antaa sarakkeen opettaja_id arvoksi mitä tahansa (esim. luvun 123), jolloin tietokannan sisältö muuttuu epämääräiseksi.
Voimme parantaa tilannetta kertomalla taulun Kurssit luonnissa, että sarake opettaja_id on viiteavain tauluun Opettajat:
CREATE TABLE Kurssit (id INTEGER PRIMARY KEY, nimi TEXT, opettaja_id INTEGER REFERENCES Opettajat);
Tämän jälkeen voimme luottaa siihen, että taulussa Kurssit sarakkeen opettaja_id arvot
viittaavat todellisiin riveihin taulussa Opettajat.
Huomaa, että historiallisista syistä SQLite ei oletuksena valvo viiteavainten ehtoja, vaan meidän tulee ensin suorittaa seuraava komento:
sqlite> PRAGMA foreign_keys = ON;
Tämä on SQLiten erikoisuus, ja muissa tietokannoissa viiteavaimia valvotaan aina.
Tässä on esimerkki viiteavaimen käyttämisestä:
sqlite> PRAGMA foreign_keys = ON;
sqlite> CREATE TABLE Opettajat (id INTEGER PRIMARY KEY, nimi TEXT);
sqlite> CREATE TABLE Kurssit (id INTEGER PRIMARY KEY, nimi TEXT, opettaja_id INTEGER
...> REFERENCES Opettajat);
sqlite> INSERT INTO Opettajat (nimi) VALUES ('Kaila');
sqlite> INSERT INTO Opettajat (nimi) VALUES ('Kivinen');
sqlite> SELECT * FROM Opettajat;
1|Kaila
2|Kivinen
sqlite> INSERT INTO Kurssit (nimi, opettaja_id) VALUES ('Laskennan mallit',2);
sqlite> INSERT INTO Kurssit (nimi, opettaja_id) VALUES ('Ohjelmoinnin perusteet',123);
Error: FOREIGN KEY constraint failed
Taulussa Opettaja on kaksi opettajaa, joiden id-numerot ovat 1 ja 2. Niinpä kun koetamme lisätä tauluun Kurssit rivin, jossa opettaja_id on 123, SQLite ei salli tätä vaan saamme virheilmoituksen FOREIGN KEY constraint failed.
Viittaukset ja poistot
Viittausten ehtoihin liittyy tavallisia sarakkeiden ehtoja mutkikkaampia tilanteita, koska viittaukset ovat kahden taulun välisiä. Erityisesti mitä tapahtuu, jos taulusta yritetään poistaa rivi, johon viitataan toisen taulun rivillä?
Yleensä oletuksena tietokannoissa riviä ei voi poistaa, jos siihen on viittaus muualta. Esimerkiksi jos koetamme äskeisen esimerkin päätteeksi poistaa taulusta Opettajat rivin 2, tämä ei onnistu, koska siihen viitataan taulussa Kurssit:
sqlite> DELETE FROM Opettajat WHERE id=2;
Error: FOREIGN KEY constraint failed
Halutessamme voimme kuitenkin määrittää taulun luonnissa tarkemmin, mitä tapahtuu tässä tilanteessa. Esimerkiksi yksi vaihtoehto on ON DELETE CASCADE, mikä tarkoittaa, että rivin poistuessa myös siihen viittaavat rivit poistetaan. Saamme tämän aikaan näin:
CREATE TABLE Kurssit (id INTEGER PRIMARY KEY, nimi TEXT,
opettaja_id INTEGER REFERENCES Opettajat ON DELETE CASCADE);
Nyt jos tietokannasta poistetaan opettaja, niin samalla poistetaan automaattisesti kaikki kurssit, joita hän opettaa. Tämä voi kuitenkin olla kyseenalainen vaihtoehto, koska tämän seurauksena tietokannan tauluista voi kadota yllättäen tietoa.
Mahdollisia vaihtoehtoja ON DELETE -osassa ovat:
NO ACTION: “älä tee mitään” (oletus)RESTRICT: estä poistaminenCASCADE: poista myös viittaavat rivitSET NULL: muuta viittaukset arvoksiNULLSET DEFAULT: muuta viittaukset oletusarvoksi
Hämmentävä seikka on, että myös oletusvaihtoehto NO ACTION estää rivin poistamisen, vaikka nimestä voisi päätellä muuta. Vaihtoehdot NO ACTION ja RESTRICT toimivat käytännössä lähes samalla tavalla, mutta tietokannasta riippuen niiden toiminnassa voi olla eroja joissain erikoistilanteissa.
Transaktiot
Transaktio on joukko peräkkäisiä SQL-komentoja, jotka tietokantajärjestelmä lupaa suorittaa yhtenä kokonaisuutena. Tietokannan käyttäjä voi luottaa siihen, että joko (1) kaikki komennot suoritetaan ja muutokset jäävät pysyvästi tietokantaan tai (2) transaktio keskeytyy eivätkä komennot aiheuta mitään muutoksia tietokantaan.
Transaktioiden yhteydessä esiintyy usein ihanteena kirjainyhdistelmä ACID, joka tulee seuraavista sanoista:
- Atomicity: Transaktiossa olevat komennot suoritetaan yhtenä kokonaisuutena.
- Consistency: Transaktio säilyttää tietokannan sisällön eheänä.
- Isolation: Transaktiot suoritetaan eristyksessä toisistaan.
- Durability: Loppuun viedyn transaktion tekemät muutokset jäävät pysyviksi.
Transaktion vaiheet
Itse asiassa transaktio on hyvin arkipäiväinen asia tietokannan käyttämisessä, sillä oletuksena jokainen suoritettava SQL-komento on oma transaktionsa. Tarkastellaan esimerkiksi seuraavaa komentoa, joka kasvattaa jokaisen tuotteen hintaa yhdellä:
UPDATE Tuotteet SET hinta=hinta+1;
Koska komento suoritetaan transaktiona, voimme luottaa siihen, että joko jokaisen tuotteen hinta todella kasvaa yhdellä tai sitten minkään tuotteen hinta ei muutu. Jälkimmäinen voi tapahtua esimerkiksi silloin, kun sähköt katkeavat kesken päivityksen. Siinäkään tapauksessa ei siis voi käydä niin, että vain osa hinnoista muuttuu.
Usein kuitenkin sana transaktio viittaa erityisesti siihen, että kokonaisuuteen kuuluu useampi SQL-komento. Tällöin annamme ensin komennon BEGIN, joka aloittaa transaktion, sitten kaikki transaktioon kuuluvat komennot tavalliseen tapaan ja lopuksi komennon COMMIT, joka päättää transaktion.
Klassinen esimerkki transaktiosta on tilanne, jossa pankissa siirretään rahaa tililtä toiselle. Esimerkiksi seuraava transaktio siirtää 100 euroa Maijan tililtä Uolevin tilille:
BEGIN;
UPDATE Tilit SET saldo=saldo-100 WHERE omistaja='Maija';
UPDATE Tilit SET saldo=saldo+100 WHERE omistaja='Uolevi';
COMMIT;
Transaktion ideana on, että mitään pysyvää muutosta ei tapahdu ennen komentoa COMMIT. Niinpä yllä olevassa esimerkissä ei ole mahdollista, että Maija menettäisi 100 euroa mutta Uolevi ei saisi mitään. Joko kummankin tilin saldo muuttuu ja rahat siirtyvät onnistuneesti tai molemmat saldot säilyvät entisellään.
Jos transaktio keskeytyy jostain syystä ennen komentoa COMMIT, kaikki transaktiossa tehdyt muutokset peruuntuvat. Yksi syy transaktion keskeytymiseen on jokin häiriö tietokoneen toiminnassa (kuten sähköjen katkeaminen), mutta voimme myös itse halutessamme keskeyttää transaktion antamalla komennon ROLLBACK.
Transaktioiden kokeilu
Hyvä tapa saada ymmärrystä transaktioista on kokeilla käytännössä, miten ne toimivat. Tässä on esimerkkinä yksi keskustelu SQLiten kanssa:
sqlite> CREATE TABLE Tilit (id INTEGER PRIMARY KEY, omistaja TEXT, saldo INTEGER);
sqlite> INSERT INTO Tilit (omistaja,saldo) VALUES ('Uolevi',350);
sqlite> INSERT INTO Tilit (omistaja,saldo) VALUES ('Maija',600);
sqlite> SELECT * FROM Tilit;
1|Uolevi|350
2|Maija|600
sqlite> BEGIN;
sqlite> UPDATE Tilit SET saldo=saldo-100 WHERE omistaja='Maija';
sqlite> SELECT * FROM Tilit;
1|Uolevi|350
2|Maija|500
sqlite> ROLLBACK;
sqlite> SELECT * FROM Tilit;
1|Uolevi|350
2|Maija|600
sqlite> BEGIN;
sqlite> UPDATE Tilit SET saldo=saldo-100 WHERE omistaja='Maija';
sqlite> UPDATE Tilit SET saldo=saldo+100 WHERE omistaja='Uolevi';
sqlite> COMMIT;
sqlite> SELECT * FROM Tilit;
1|Uolevi|450
2|Maija|500
Alkutilanteessa Uolevin tilillä on 350 euroa ja Maijan tilillä on 600 euroa. Ensimmäisessä transaktiossa poistamme ensin Maijan tililtä 100 euroa, mutta sen jälkeen tulemme toisiin ajatuksiin ja keskeytämme transaktion. Niinpä transaktiossa tehty muutos peruuntuu ja tilien saldot ovat samat kuin alkutilanteessa. Toisessa transaktiossa viemme kuitenkin transaktion loppuun, minkä seurauksena Uolevin tilillä on 450 euroa ja Maijan tilillä on 500 euroa.
Huomaa, että transaktion sisällä muutokset kyllä näkyvät, vaikka niitä ei olisi tehty vielä pysyvästi tietokantaan. Esimerkiksi ensimmäisen transaktion SELECT-kysely antaa Maijan tilin saldoksi 500 euroa, koska edellinen UPDATE-komento muutti saldoa.
Transaktiot ohjelmoinnissa
Transaktiokomentoja (BEGIN, COMMIT, jne.) voi suorittaa ohjelmoinnissa samaan tapaan kuin muitakin SQL-komentoja. Esimerkiksi seuraava koodi lisää tauluun Tuotteet tuhat riviä for-silmukassa yhden transaktion sisällä:
db.execute("BEGIN")
for i in range(1,1000+1):
db.execute("INSERT INTO Tuotteet (nimi, hinta) VALUES (?,?)", ["tuote"+str(i), 1])
db.execute("COMMIT")
Koska koodi on transaktion sisällä, koodi joko lisää kaikki rivit tietokantaan tai ei yhtään riviä, jos transaktio epäonnistuu jostain syystä.
Tässä tapauksessa transaktion sivuvaikutuksena on myös, että koodi toimii nopeammin, koska jokaista riviä ei lisätä erillisen transaktion sisällä vaan lisäys tapahtuu kokonaisuutena. Tämä auttaa tietokantaa toteuttamaan rivien lisääminen tehokkaammin.
Rinnakkaiset transaktiot
Lisämaustetta transaktioiden käsittelyyn tuo se, että tietokannalla voi olla useita käyttäjiä, joilla on meneillään samanaikaisia transaktioita. Missä määrin eri käyttäjien transaktiot tulisi eristää toisistaan?
Tämä on kysymys, johon ei ole yhtä oikeaa vastausta, vaan vastaus riippuu käyttötilanteesta ja myös tietokannan ominaisuuksista. Tavallaan paras ratkaisu olisi eristää transaktiot täydellisesti toisistaan, mutta toisaalta tämä voi haitata tietokannan käyttämistä.
SQL-standardi määrittelee transaktioiden eristystasot seuraavasti:
Taso 1 (read uncommitted)
On sallittua, että transaktio pystyy näkemään toisen transaktion tekemän muutoksen, vaikka toista transaktiota ei ole viety loppuun.
Taso 2 (read committed)
Toisin kuin tasolla 1, transaktio saa nähdä toisen transaktion tekemän muutoksen vain, jos toinen transaktio on viety loppuun.
Taso 3 (repeatable read)
Tason 2 vaatimus ja lisäksi jos transaktion aikana luetaan saman rivin sisältö useita kertoja, joka kerralla saadaan sama sisältö.
Taso 4 (serializable)
Transaktiot ovat täysin eristettyjä ja komennot käyttäytyvät samoin kuin jos transaktiot olisi suoritettu peräkkäin yksi kerrallaan jossain järjestyksessä.
Esimerkki
Tarkastellaan tilannetta, jossa tuotteen 1 hinta on aluksi 8 ja kaksi käyttäjää suorittaa samaan aikaan komentoja transaktioiden sisällä (käyttäjän 1 komennot ovat vasemmalla ja käyttäjän 2 komennot ovat oikealla):
BEGIN;
BEGIN;
UPDATE Tuotteet SET hinta=5 WHERE id=1;
SELECT hinta FROM Tuotteet WHERE id=1;
UPDATE Tuotteet SET hinta=7 WHERE id=1;
COMMIT;
SELECT hinta FROM Tuotteet WHERE id=1;
COMMIT;
Tasolla 1 käyttäjä 1 voi saada kyselyistä tulokset 5 ja 7, koska käyttäjän 2 tekemät muutokset voivat tulla näkyviin heti, vaikka käyttäjän 2 transaktioita ei ole viety loppuun.
Tasolla 2 käyttäjä 1 voi saada kyselyistä tulokset 8 ja 7, koska ensimmäisen kyselyn kohdalla toista transaktiota ei ole viety loppuun, kun taas toisen kyselyn kohdalla se on viety loppuun.
Tasoilla 3 ja 4 käyttäjä 1 saa kyselyistä tulokset 8 ja 8, koska tämä on tilanne ennen transaktion alkua eikä välissä loppuun viety transaktio saa muuttaa luettua rivin sisältöä.
Transaktiot käytännössä
Transaktioiden toteutustavat ja saatavilla olevat eristystasot riippuvat käytetystä tietokantajärjestelmästä. Esimerkiksi SQLitessä ainoa mahdollinen taso on 4, kun taas PostgreSQL toteuttaa tasot 2–4 ja oletuksena käytössä on taso 2.
Eristystaso 4 on tavallaan selkeästi paras, koska silloin transaktioiden muutokset eivät voi näkyä mitenkään toisilleen. Miksi edes muut tasot ovat olemassa ja miksi esimerkiksi PostgreSQL:n oletustaso on 2?
Hyvän eristämisen hintana on, että se voi hidastaa tai estää transaktioiden suorittamista, koska transaktion vieminen loppuun voisi aiheuttaa ristiriitaisen tilanteen. Toisaalta monissa käytännön tilanteissa riittää mainiosti heikompikin eristys, kunhan tietokannan käyttäjä on siitä tietoinen.
Hyvää tietoa rinnakkaisten transaktioiden toiminnasta saa perehtymällä käytetyn tietokannan dokumentaatioon sekä testailemalla asioita itse käytännössä. Esimerkiksi voimme käynnistää itse kaksi SQLite-tulkkia, avata niillä saman tietokannan ja sen jälkeen kirjoittaa transaktioita sisältäviä komentoja ja tehdä havaintoja.
Seuraava keskustelu näyttää edellisen esimerkin tuloksen kahdessa rinnakkain käynnissä olevassa SQLite-tulkissa:
BEGIN;
BEGIN;
UPDATE Tuotteet SET hinta=5 WHERE id=1;
SELECT hinta FROM Tuotteet WHERE id=1;
8
UPDATE Tuotteet SET hinta=7 WHERE id=1;
COMMIT;
Error: database is locked
SELECT hinta FROM Tuotteet WHERE id=1;
8
COMMIT;
Tästä näkee, että ensimmäinen transaktio tosiaan saa kummastakin kyselystä tuloksen 8. Toista transaktiota ei sen sijaan saada vietyä loppuun, vaan tulee virheviesti Error: database is locked, koska tietokanta on lukittuna samanaikaisen transaktion takia. Eristys toimii siis hyvin, mutta toista transaktiota pitäisi yrittää viedä loppuun uudestaan.
Vertailun vuoksi tässä on vastaava keskustelu PostgreSQL-tulkeissa (tasolla 2):
BEGIN;
BEGIN;
UPDATE Tuotteet SET hinta=5 WHERE id=1;
SELECT hinta FROM Tuotteet WHERE id=1;
8
UPDATE Tuotteet SET hinta=7 WHERE id=1;
COMMIT;
SELECT hinta FROM Tuotteet WHERE id=1;
7
COMMIT;
Nyt toisen transaktion muuttama arvo 7 ilmestyy ensimmäiseen transaktioon, mutta toisaalta molemmat transaktiot saadaan vietyä loppuun ongelmitta.
Miten transaktiot toimivat?
Transaktioiden toteuttaminen on kiehtova tekninen haaste tietokannoissa. Tavallaan transaktion tulee tehdä muutoksia tietokantaan, koska komennot voivat riippua edellisistä komennoista, mutta toisaalta mitään ei saa muuttaa pysyvästi ennen transaktion viemistä loppuun.
Yksi keskeinen ajatus tietokantojen taustalla on tallentaa muutoksia kahdella tavalla. Ensin kuvaus muutoksesta kirjataan lokitiedostoon (write-ahead log), jota voi ajatella luettelona suoritetuista komennoista. Vasta tämän jälkeen muutokset tehdään tietokannan varsinaisiin tietorakenteisiin. Nyt jos jälkimmäisessä vaiheessa sattuu jotain yllättävää, muutokset ovat jo tallessa lokitiedostossa ja ne voidaan suorittaa myöhemmin uudestaan.
Transaktioiden yhteydessä tietokantajärjestelmän täytyy myös pitää kirjaa siitä, mitkä muutokset ovat minkäkin meneillään olevan transaktion tekemiä. Käytännössä tauluihin voidaan tallentaa rivimuutoksia, jotka näkyvät vain tietyille transaktioille. Sitten jos transaktio pääsee loppuun asti, nämä muutokset liitetään taulun pysyväksi sisällöksi.
Kyselyjen suoritus
SQL-kieli on tietokannan käyttäjälle mukava kyselyjen tekemisessä, koska käyttäjän riittää kuvata, mitä tietoa hän haluaa hakea, ja tietokantajärjestelmä hoitaa loput. Niinpä tietokantajärjestelmän on tärkeää pystyä löytämään jokin tehokas tapa toteuttaa käyttäjän antama kysely ja toimittaa kyselyn tulokset käyttäjälle.
Kyselyn suunnitelma
Monet tietokantajärjestelmät kertovat pyydettäessä suunnitelmansa, miten annettu kysely aiotaan suorittaa. Tämän avulla voimme tutkia tietokantajärjestelmän sisäistä toimintaa.
Tarkastellaan esimerkkinä kyselyä, joka hakee retiisin tiedot taulusta Tuotteet:
SELECT * FROM Tuotteet WHERE nimi='retiisi';
Kun laitamme SQLitessä kyselyn eteen sanan EXPLAIN, saamme seuraavan tapaisen selostuksen suunnitelmasta:
sqlite> EXPLAIN SELECT * FROM Tuotteet WHERE nimi='retiisi';
addr opcode p1 p2 p3 p4 p5 comment
---- ------------- ---- ---- ---- ------------- -- -------------
0 Init 0 12 0 00 Start at 12
1 OpenRead 0 2 0 3 00 root=2 iDb=0; Tuotteet
2 Rewind 0 10 0 00
3 Column 0 1 1 00 r[1]=Tuotteet.nimi
4 Ne 2 9 1 (BINARY) 52 if r[2]!=r[1] goto 9
5 Rowid 0 3 0 00 r[3]=rowid
6 Copy 1 4 0 00 r[4]=r[1]
7 Column 0 2 5 00 r[5]=Tuotteet.hinta
8 ResultRow 3 3 0 00 output=r[3..5]
9 Next 0 3 0 01
10 Close 0 0 0 00
11 Halt 0 0 0 00
12 Transaction 0 0 1 0 01 usesStmtJournal=0
13 TableLock 0 2 0 Tuotteet 00 iDb=0 root=2 write=0
14 String8 0 2 0 retiisi 00 r[2]='retiisi'
15 Goto 0 1 0 00
SQLite muuttaa kyselyn tietokannan sisäiseksi ohjelmaksi, joka hakee tietoa tauluista. Tässä tapauksessa ohjelman suoritus alkaa riviltä 12, jossa alkaa transaktio, ja sitten rivillä 14 rekisteriin 2 sijoitetaan hakuehdossa oleva merkkijono “retiisi”. Tämän jälkeen suoritus siirtyy riville 1, jossa aloitetaan taulun Tuotteet käsittely, ja rivit 2–9 muodostavat silmukan, joka etsii hakuehtoa vastaavat rivit taulusta.
Voimme myös pyytää tiiviimmän suunnitelman laittamalla kyselyn eteen sanat EXPLAIN QUERY PLAN. Tällöin tulos voi olla seuraava:
sqlite> EXPLAIN QUERY PLAN SELECT * FROM Tuotteet WHERE nimi='retiisi';
0|0|0|SCAN TABLE Tuotteet
Tässä SCAN TABLE Tuotteet tarkoittaa, että kysely käy läpi taulun Tuotteet rivit.
Kyselyn optimointi
Jos kyselyssä haetaan tietoa vain yhdestä taulusta, kysely on yleensä helppo suorittaa, mutta todelliset haasteet tulevat vastaan usean taulun kyselyissä. Tällöin tietokantajärjestelmän tulee osata optimoida kyselyn suorittamista eli muodostaa hyvä suunnitelma, jonka avulla halutut tiedot saadaan kerättyä tehokkaasti tauluista.
Tarkastellaan esimerkkinä seuraavaa kyselyä, joka listaa kurssien ja opettajien nimet:
SELECT K.nimi, O.nimi FROM Kurssit K, Opettajat O WHERE K.opettaja_id = O.id;
Koska kysely kohdistuu kahteen tauluun, olemme ajatelleet kyselyn toiminnan niin, että se muodostaa ensin kaikki rivien yhdistelmät tauluista Kurssit ja Opettajat ja valitsee sitten ne rivit, joilla pätee ehto K.opettaja_id = O.id. Tämä on hyvä ajattelutapa, mutta tämä ei vastaa sitä, miten kunnollinen tietokantajärjestelmä toimii.
Ongelmana on, että tauluissa Kurssit ja Opettajat voi molemmissa olla suuri määrä rivejä. Esimerkiksi jos kummassakin taulussa on miljoona riviä, rivien yhdistelmiä olisi miljoona miljoonaa ja veisi valtavasti aikaa muodostaa ja käydä läpi kaikki yhdistelmät.
Tässä tilanteessa tietokantajärjestelmän pitääkin ymmärtää, mitä käyttäjä oikeastaan on hakemassa ja miten kyselyssä annettu ehto rajoittaa tulosrivejä. Käytännössä riittää käydä läpi kaikki taulun Kurssit rivit ja etsiä jokaisen rivin kohdalla jotenkin tehokkaasti yksittäinen haluttu rivi taulusta Opettajat.
Voimme taas pyytää SQLiteä selittämään kyselyn suunnitelman:
sqlite> EXPLAIN QUERY PLAN SELECT K.nimi, O.nimi FROM Kurssit K, Opettajat O WHERE K.opettaja_id = O.id;
0|0|0|SCAN TABLE Kurssit AS K
0|1|1|SEARCH TABLE Opettajat AS O USING INTEGER PRIMARY KEY (rowid=?)
Tämä kysely käy läpi taulun Kurssit rivit (SCAN TABLE Kurssit) ja hakee tietoa taulusta Opettajat pääavaimen avulla (SEARCH TABLE Opettajat). Jälkimmäinen tarkoittaa, että kun käsittelyssä on tietty taulun Kurssit rivi, kysely hakee tehokkaasti taulusta Opettajat rivin, jossa pääavain O.id on sama kuin K.opettaja_id.
Mutta miten käytännössä taulusta Opettajat voi hakea tehokkaasti? Tämä onnistuu käyttämällä indeksiä, joihin tutustumme heti seuraavaksi.
Indeksit
Indeksi on tietokannan taulun yhteyteen tallennettu hakemistorakenne, jonka tavoitteena on tehostaa tauluun liittyvien kyselyiden suorittamista. Indeksin avulla tietokantajärjestelmä voi selvittää tehokkaasti, missä päin taulua on rivejä, jotka täsmäävät tiettyyn hakuehtoon.
Indeksiä voi ajatella samalla tavalla kuin kirjan lopussa olevaa hakemistoa, jossa kerrotaan hakusanoista, millä kirjan sivuilla ne esiintyvät. Hakemiston avulla löydämme tietyn sanan sijainnit paljon nopeammin kuin lukemalla koko kirjan läpi.
Pääavaimen indeksi
Kun tietokantaan luodaan taulu, sen pääavain saa automaattisesti indeksin. Tämän seurauksena voimme suorittaa tehokkaasti hakuja, joissa ehto liittyy pääavaimeen.
Esimerkiksi kun luomme SQLitessä taulun
CREATE TABLE Tuotteet (id INTEGER PRIMARY KEY, nimi TEXT, hinta INTEGER);
niin taululle luodaan indeksi sarakkeelle id ja voimme etsiä tehokkaasti tuotteita id-numeron perusteella. Tämän ansiosta esimerkiksi seuraava kysely toimii tehokkaasti:
SELECT hinta FROM Tuotteet WHERE id=3;
Voimme varmistaa tämän kysymällä kyselyn suunnitelman:
sqlite> EXPLAIN QUERY PLAN SELECT hinta FROM Tuotteet WHERE id=3;
selectid order from detail
---------- ---------- ---------- ---------------------------------------------------------
0 0 0 SEARCH TABLE Tuotteet USING INTEGER PRIMARY KEY (rowid=?)
Suunnitelmassa näkyy SEARCH TABLE, mikä tarkoittaa, että kysely pystyy hakemaan taulusta tietoa tehokkaasti indeksin avulla.
Indeksin luominen
Pääavaimen indeksi on kätevä, mutta voimme haluta myös etsiä tietoa jonkin muun sarakkeen perusteella. Esimerkiksi seuraava kysely hakee rivit sarakkeen hinta perusteella:
SELECT nimi FROM Tuotteet WHERE hinta=4;
Tämä kysely ei ole oletuksena tehokas, koska sarakkeelle hinta ei ole indeksiä. Näemme tämän pyytämällä taas selitystä kyselystä:
sqlite> EXPLAIN QUERY PLAN SELECT nimi FROM Tuotteet WHERE hinta=4;
selectid order from detail
---------- ---------- ---------- -------------------
0 0 0 SCAN TABLE Tuotteet
Nyt suunnitelmassa näkyy SCAN TABLE, mikä tarkoittaa, että kysely joutuu käymään läpi taulun kaikki rivit. Tämä on hidasta, jos taulussa on paljon rivejä.
Voimme kuitenkin luoda uuden indeksin, joka tehostaa saraketta hinta käyttäviä kyselyitä. Saamme luotua indeksin komennolla CREATE INDEX näin:
CREATE INDEX idx_hinta ON Tuotteet (hinta);
Tässä idx_hinta on indeksin nimi, jolla voimme viitata siihen myöhemmin. Indeksi toimii luonnin jälkeen täysin automaattisesti, eli tietokantajärjestelmä osaa käyttää sitä kyselyissä
ja huolehtii sen päivittämisestä.
Indeksin luomisen jälkeen voimme kysyä uudestaan kyselyn suunnitelmaa:
sqlite> EXPLAIN QUERY PLAN SELECT nimi FROM Tuotteet WHERE hinta=4;
selectid order from detail
---------- ---------- ---------- -----------------------------------------------------
0 0 0 SEARCH TABLE Tuotteet USING INDEX idx_hinta (hinta=?)
Indeksin ansiosta suunnitelmassa ei lue enää SCAN TABLE vaan SEARCH TABLE. Suunnitelmassa näkyy myös, että aikomuksena on hyödyntää indeksiä idx_hinta.
Lisää käyttötapoja
Voimme käyttää indeksiä myös kyselyissä, joissa haemme pienempiä tai suurempia arvoja. Esimerkiksi sarakkeelle hinta luodun indeksin avulla voimme etsiä vaikkapa rivejä, joille pätee ehto hinta<3 tai hinta>=8.
Indeksi on myös mahdollista luoda usean sarakkeen perusteella. Esimerkiksi voisimme luoda indeksin näin:
CREATE INDEX idx_hinta ON Tuotteet (hinta,nimi);
Tässä indeksissä rivit on järjestetty ensisijaisesti hinnan ja toissijaisesti nimen mukaan. Indeksi tehostaa hakuja, joissa hakuperusteena on joko pelkkä hinta tai yhdessä hinta ja nimi. Kuitenkaan indeksi ei tehosta hakuja, joissa hakuperusteena on pelkkä nimi.
Miten indeksi toimii?
Indeksi tarvitsee tuekseen hakemistorakenteen, josta voi hakea tehokkaasti rivejä sarakkeen arvon perusteella. Tämä voidaan toteuttaa esimerkiksi puurakenteena, jonka avaimina on sarakkeiden arvoja.
Asiaan liittyvää teoriaa käsitellään tarkemmin kurssilla Tietorakenteet ja algoritmit binäärihakupuiden yhteydessä. Tyypillisiä tietokantojen yhteydessä käytettäviä puurakenteita ovat B-puu ja sen muunnelmat.
Milloin luoda indeksi?
Periaatteessa voisi ajatella, että taulun jokaiselle sarakkeelle kannattaa luoda indeksi, jolloin monenlaiset kyselyt ovat nopeita. Tämä ei ole kuitenkaan käytännössä hyvä idea.
Vaikka indeksit tehostavat kyselyitä, niissä on myös kaksi ongelmaa: indeksin hakemistorakenne vie tilaa ja indeksi myös hidastaa tiedon lisäämistä ja muuttamista. Jälkimmäinen johtuu siitä, että kun taulun sisältö muuttuu, niin muutos täytyy myös päivittää kaikkiin tauluun liittyviin indekseihin. Indeksiä ei siis kannata luoda huvin vuoksi.
Hyvä syy indeksin luontiin on, että haluamme suorittaa usein tietynlaisia kyselyitä ja ne toimivat hitaasti, koska tietokantajärjestelmä joutuu käymään läpi turhaan jonkin taulun kaikki rivit kyselyn aikana. Tällöin voimme lisätä taululle indeksin, jonka avulla tällaiset kyselyt toimivat jatkossa tehokkaasti.
Indekseillä on käytännössä suuri vaikutus tietokantojen tehokkuuteen. Moni tietokanta toimii hitaasti sen takia, että siitä puuttuu oleellisia indeksejä.
Huomaa, että indeksit ovat myös yksi esimerkki siitä, miten toisteinen tieto voi tehostaa kyselyjä. Indekseissä kuitenkaan toisteista tietoa ei tallenneta tauluun vaan taulun ulkopuolelle erilliseen hakemistorakenteeseen.
8. Tietokantojen teoria
Tietokannan sisällön esittäminen relaatiomallin mukaisesti tauluina ja riveinä tuntuu nykyään lähes itsestään selvältä tavalta, mutta tämä oli aikoinaan mullistava idea tietokanta-alalla. Tässä luvussa tutustumme relaatiomallin matemaattiseen taustaan, joka syntyi 1970-luvulla.
Matemaattinen tausta
Joukko
Joukko (set) on kokoelma alkioita. Esimerkiksi \(A=\{1,2,3,4,5\}\) ja \(B=\{apina, banaani, cembalo\}\) ovat joukkoja.
Merkintä \(\mid S \mid\) tarkoittaa joukon \(S\) alkioiden määrää. Äskeisessä esimerkissä \(\mid A \mid=5\) ja \(\mid B \mid =3\).
Merkintä \(x \in S\) tarkoittaa, että alkio \(x\) kuuluu joukkoon \(S\).
Joukon alkioilla ei ole tiettyä järjestystä. Esimerkiksi \(\{1,2,3\}\), \(\{1,3,2\}\) ja \(\{2,3,1\}\) tarkoittavat samaa joukkoa.
Tietty alkio voi esiintyä joukossa enintään kerran. Esimerkiksi \(\{1,2,1\}\) ei ole joukko, koska alkio \(1\) esiintyy kahdesti.
Osajoukko
Osajoukko (subset) sisältää osan joukon alkioista. Esimerkiksi joukon \(\{1,2,3\}\) osajoukot ovat \(\emptyset\), \(\{1\}\), \(\{2\}\), \(\{3\}\), \(\{1,2\}\), \(\{1,3\}\), \(\{2,3\}\) ja \(\{1,2,3\}\). Merkintä \(\emptyset\) tarkoittaa tyhjää joukkoa.
Merkintä \(A \subset B\) tarkoittaa, että joukko \(A\) on joukon \(B\) osajoukko.
Osajoukko on aito (proper), jos siinä ei ole kaikkia joukon alkioita.
Kun joukossa on \(n\) alkiota, siitä voidaan muodostaa \(2^n\) osajoukkoa. Esimerkiksi joukossa \(\{1,2,3\}\) on \(3\) alkiota, joten osajoukkoja on \(2^3=8\).
Monikko
Monikko (tuple) on lista alkioita tietyssä järjestyksessä. Esimerkiksi \((1,3,2)\) on monikko, jossa on \(3\) alkiota.
Monikossa alkioiden järjestyksellä on merkitystä. Esimerkiksi \((1,2,3)\), \((1,3,2)\) ja \((2,3,1)\) ovat kolme eri monikkoa.
Monikossa sama alkio voi toistua monta kertaa. Esimerkiksi \((1,2,1)\) on monikko, jossa toistuu kahdesti alkio \(1\).
Karteesinen tulo
Karteesinen tulo (Cartesian product) \(S_1 \times S_2 \times \dots \times S_k\) sisältää kaikki monikot, jotka muodostuvat valitsemalla järjestyksessä yksi alkio jokaisesta joukosta \(S_1,S_2,\dots,S_k\).
Kun \(A=\{1,2,3\}\) ja \(B=\{x,y,z\}\), niin
\[A \times B = \{(1,x),(1,y),(1,z),(2,x),(2,y),(2,z),(3,x),(3,y),(3,z)\}.\]Kun \(A=\{1,2,3\}\), \(B=\{x\}\) ja \(C=\{1,2\}\), niin
\[A \times B \times C = \{(1,x,1), (1,x,2), (2,x,1), (2,x,2), (3,x,1), (3,x,2)\}.\]Karteesisen tulon alkioiden määrä on \(\mid S_1 \mid \cdot \mid S_2 \mid \dots \mid S_k \mid\). Esimerkiksi kun \(\mid A \mid = 3\), \(\mid B \mid = 1\) ja \(\mid C \mid = 2\), karteesinen tulo \(A \times B \times C\) muodostuu \(3 \cdot 1 \cdot 2 = 6\) alkiosta.
Relaatio
Relaatio (relation) on karteesisen tulon osajoukko. Kun \(A=\{1,2,3\}\) ja \(B=\{x,y,z\}\), niin mahdollisia karteesisen tulon \(A \times B\) relaatioita ovat esimerkiksi seuraavat:
\[R_1 = \{(1,x),(1,y),(1,z)\}\] \[R_2 = \{(1,x),(2,x),(2,z),(3,y)\}\] \[R_3 = \{(2,y)\}\]Relaatio tarkoittaa siis sitä, että valitaan jokin osajoukko kaikista mahdollisista alkioiden muodostamista yhdistelmistä.
Karteesisella tulolla \(S_1 \times S_2 \times \dots \times S_k\) on kaikkiaan \(2^{\mid S_1 \mid \cdot \mid S_2 \mid \dots \mid S_k \mid}\) mahdollista relaatiota.
Taulu relaationa
Tietokannan taulu voidaan esittää matemaattisesti relaationa, jonka jokainen monikko vastaa yhtä taulun riviä. Kun taulussa on \(k\) saraketta, relaatiossa jokaisessa monikossa on vastaavasti \(k\) alkiota, joista käytetään nimeä attribuutti. Relaation taustalla on karteesinen tulo
\[S_1 \times S_2 \times \dots \times S_k,\]jossa joukot \(S_1,S_2,\dots,S_k\) ilmaisevat, mitä arvoja kussakin attribuutissa voi olla eli kunkin attribuutin tyypin.
Esimerkki
Tarkastellaan esimerkkinä taulua Tuotteet, jossa on tietoa tuotteista:
| Tuotteet | ||
|---|---|---|
| id | nimi | hinta |
| 1 | retiisi | 7 |
| 2 | porkkana | 5 |
| 3 | nauris | 4 |
| 4 | lanttu | 8 |
| 5 | selleri | 4 |
Tämä taulu vastaa relaatiota
\[T=\{(1,retiisi,7),(2,porkkana,5),(3,nauris,4),(4,lanttu,8),(5,selleri,4)\},\]jonka jokainen monikko muodostuu kolmesta attribuutista id, nimi ja hinta.
Tässä tapauksessa relaation taustalla on karteesinen tulo \(S_1 \times S_2 \times S_3\). Joukot \(S_1,S_2,S_3\) määrittelevät attribuuttien tyypit eli jokainen joukko sisältää kaikki arvot, joita vastaavassa attribuutissa voi olla.
Esimerkiksi attribuutti id on positiivinen kokonaisluku, joten \(S_1\) voisi olla \(\{1,2,3,\dots\}\) eli ääretön joukko, joka sisältää kaikki positiiviset kokonaisluvut. Toinen mahdollisuus on, että id-numerolla on yläraja, kuten yleensä käytännön tietokannoissa. Esimerkiksi jos id-numero on 64-bittinen kokonaisluku, \(S_1\) voisi olla \(\{1,2,3,\dots,2^{64}-1\}\).
Teoria vs. käytäntö
SQL-tietokannat perustuvat relaatiomalliin, mutta ne eivät kuitenkaan täysin noudata sitä.
Yksi ero on, että relaatiossa jokainen monikko on erilainen (koska relaatio on joukko), mutta SQL-taulussa ei ole tätä rajoitusta. Esimerkiksi voimme luoda seuraavasti taulun Testi ja lisätä siihen kolme samanlaista riviä:
sqlite> CREATE TABLE Testi (x INTEGER);
sqlite> INSERT INTO Testi VALUES (1);
sqlite> INSERT INTO Testi VALUES (1);
sqlite> INSERT INTO Testi VALUES (1);
sqlite> SELECT * FROM Testi;
1
1
1
Usein tosin SQL-taulussa on sarake id, joka takaa, että taulussa ei ole kahta samanlaista riviä, koska jokaisella rivillä on eri id-numero.
Toinen ero on, että relaatiossa jokaisella monikon attribuutilla tulee olla arvo mutta SQL-taulussa sarakkeessa voi olla NULL eli arvo puuttuu.
Relaatio-operaatiot
Relaatio-operaatioiden avulla olemassa olevista relaatioista voidaan muodostaa uusi relaatio. Tämä vastaa SQL:ssä kyselyä, jossa tauluista muodostetaan tulostaulu. Tutustumme seuraavaksi esimerkkinä kolmeen keskeiseen relaatio-operaatioon: projektio, restriktio ja liitos.
Projektio
Projektio \(\Pi\) muodostaa relaation, jossa monikoista valitaan tietyt attribuutit. Projektio vastaa SQL-kyselyä, jossa valitaan tietyt sarakkeet taulusta. Esimerkiksi projektio \(\Pi_{nimi,hinta}(T)\) vastaa SQL-kyselyä SELECT nimi, hinta FROM Tuotteet.
Esimerkkejä:
\[\Pi_{nimi}(T) = \{(retiisi),(porkkana),(nauris),(lanttu),(selleri)\}\] \[\Pi_{hinta}(T) = \{(7),(5),(4),(8)\}\] \[\Pi_{nimi,hinta}(T) = \{(retiisi,7),(porkkana,5),(nauris,4),(lanttu,8),(selleri,4)\}\]Huomaa, että mahdolliset toistuvat monikot suodattuvat pois projektiosta. Tämän takia projektiossa \(\Pi_{hinta}(T)\) on vain neljä monikkoa, koska kahdella tuotteella on sama hinta.
Restriktio
Restriktio \(\sigma\) muodostaa relaation, jossa on tietyt ehdot täyttävät monikot. Restriktio vastaa SQL-kyselyä, jossa rivit valitaan WHERE-osassa. Esimerkiksi restriktio \(\sigma_{hinta \le 5}(T)\) vastaa SQL-kyselyä SELECT * FROM Tuotteet WHERE hinta <= 5.
Esimerkkejä:
\[\sigma_{nimi = nauris}(T)=\{(3,nauris,4)\}\] \[\sigma_{hinta = 4}(T)=\{(3,nauris,4),(5,selleri,4)\}\] \[\sigma_{hinta \le 5}(T)=\{(2,porkkana,5),(3,nauris,4),(5,selleri,4)\}\]Yhdistämällä projektio ja restriktio saadaan vastine esimerkiksi SQL-kyselylle SELECT nimi FROM Tuotteet WHERE hinta <= 5:
Liitos
Liitos \(\bowtie\) muodostaa relaation, jonka monikot on koostettu kahden relaation pohjalta. Tämä vastaa SQL:ssä kahden taulun kyselyä.
Tarkastellaan esimerkkinä seuraavia tauluja Henkilot ja Yritykset:
| Henkilot | ||
|---|---|---|
| id | nimi | yritys_id |
| 1 | Maija | 1 |
| 2 | Liisa | 1 |
| 3 | Kaaleppi | 3 |
| Yritykset | ||
|---|---|---|
| id | nimi | |
| 1 | ||
| 2 | Amazon | |
| 3 | ||
Näitä tauluja vastaavat seuraavat relaatiot:
\[H = \{(1,Maija,1),(2,Liisa,1),(3,Kaaleppi,3)\}\] \[Y = \{(1,Google),(2,Amazon),(3,Facebook)\}\]Nyt kyselyä SELECT * FROM Henkilot H, Yritykset Y WHERE H.yritys_id = Y.id vastaa seuraava relaatio-operaatio:
Yhdistämällä tähän projektion saamme haettua kunkin henkilön nimen ja yrityksen nimen:
\[\Pi_{H.nimi,Y.nimi}({H\ \bowtie\ Y \atop \small H.yritys\_id = Y.id}) = \{(Maija,Google),(Liisa,Google),(Kaaleppi,Facebook)\}\]Teoria vs. käytäntö
Relaatio-operaatioiden avulla voidaan toteuttaa hakuja samaan tapaan kuin SQL-kyselyillä, mutta tässäkin SQL-kielessä on joitakin eroja.
Kuten näimme aiemmin, projektio \(\Pi_{hinta}(T)\) sisältää jokaisen eri hinnan vain kerran, kun taas kyselyn SELECT hinta FROM Tuotteet tulostaulussa voi olla monta kertaa sama hinta. SQL:ssä on itse asiassa kaksi eri tapaa hakea tietoa:
SELECT ALL ...: haetaan kaikki rivit, myös toistuvat rivitSELECT DISTINCT ...: haetaan jokainen erilainen rivi vain kerran
Ensimmäinen tapa on oletus ja sanaa ALL ei käytetä yleensä, mutta toistuvat rivit voidaan poistaa sanan DISTINCT avulla. Tarkasti ottaen projektiota \(\Pi_{hinta}(T)\) vastaa siis kysely SELECT DISTINCT hinta FROM Tuotteet.
Lisäksi SQL:ssä rivien järjestyksellä voi olla väliä, kun taas relaation monikoilla ei ole järjestystä. Rivien järjestys näkyy SQL:ssä esimerkiksi kyselyssä, jonka lopussa on ORDER BY, jolloin tulostaulun rivit ovat halutussa järjestyksessä. Relaatio-operaatioilla ei ole mahdollista toteuttaa tällaista hakua.
Avaimet ja riippuvuudet
Yliavain (superkey) on attribuuttien yhdistelmä, joka on varmasti erilainen jokaisessa relaation monikossa. Yliavain yksilöi siis jokaisen relaatiossa olevan monikon.
Kandidaattiavain (candidate key) eli avain (key) on minimaalinen yliavain. Tämä tarkoittaa, että jos poistetaan mikä tahansa attribuutti, niin kyseessä ei ole enää yliavain.
Pääavain (primary key) on yksi avaimista, joka on nostettu erikoisasemaan.
Esimerkki
Tarkastellaan esimerkkinä tuotteita kuvaavaa relaatiota, jonka attribuutit ovat id, nimi ja hinta.
Koska attribuutti id yksilöi jokaisen monikon, se on yliavain. Myös yhdistelmät (id, nimi), (id, hinta) ja (id, nimi, hinta) ovat yliavaimia, koska niiden osana on attribuutti id. Kuitenkin näistä yliavaimista vain id on avain, koska muut yliavaimet eivät ole minimaalisia.
Attribuutti hinta ei selkeästi ole yliavain, koska monella tuotteella voi olla sama hinta. Attribuutti nimi on yliavain siinä tapauksessa, että usealla tuotteella ei voi olla samaa nimeä. Yhdistelmä (nimi, hinta) on yliavain, jos ei voi olla kahta tuotetta, joilla olisi sekä sama nimi että sama hinta. Riippuu siis tietoon liittyvistä oletuksista, mitkä attribuuttien yhdistelmät ovat yliavaimia.
Avaimen valinta
Avain voi olla joko luonnollinen avain (natural key) tai sijaisavain (surrogate key). Luonnollinen avain muodostuu alkuperäisestä tiedosta, kun taas sijaisavain on lisätty mukaan nimenomaan sen takia, että siitä tulisi avain. Esimerkiksi nimi on luonnollinen avain, kun taas id on sijaisavain.
Tietokantojen teoriassa näkee usein käytettävän luonnollisia avaimia, mutta käytännössä on hyvin tavallista käyttää id-numeroa tai vastaavaa sijaisavainta. Tässä on etuna, että id-numero on kompakti tieto, joka kelpaa varmasti avaimeksi. Jos valittaisiin luonnollinen avain, siihen kuuluisi ehkä monia attribuutteja ja pitäisi pohtia, riittävätkö attribuutit varmasti yksilöimään monikon kaikissa tapauksissa.
Funktionaalinen riippuvuus
Funktionaalinen riippuvuus (functional dependency) \(A \to B\) tarkoittaa, että attribuutit \(A\) määräävät attribuutit \(B\). Toisin sanoen jos relaatiossa on kaksi monikkoa, joissa attribuutit \(A\) ovat samat, niin myös attribuutit \(B\) ovat samat.
Esimerkiksi jos relaatiossa on attribuutit postinumero ja kaupunki, siinä on funktionaalinen riippuvuus postinumero \(\to\) kaupunki, koska postinumerosta voidaan päätellä kaupunki. Ei voi olla kahta monikkoa, joissa olisi sama postinumero mutta eri kaupunki.
Attribuutit \(A\) muodostavat yliavaimen tarkalleen silloin, kun \(A \to B\) pätee mille tahansa attribuuteille \(B\). Tässä tapauksessa koska \(A\) on yliavain, relaatiossa ei voi olla kahta monikkoa, jossa attribuutit \(A\) ovat samat.
Normaalimuodot
Normaalimuodot ovat tietokannan suunnitteluun liittyviä vaatimuksia, joiden tavoitteena on edistää tiedon eheyttä ja helpottaa tietokannan käyttämistä.
Ensimmäinen normaalimuoto vaatii, että tietokannassa on käytössä relaatiomalli. SQL:ssä määritelty taulu toteuttaa automaattisesti ensimmäisen normaalimuodon.
Toinen ja kolmas normaalimuoto liittyvät attribuuttien riippuvuuksiin. Näiden pohjalta on edelleen kehitetty Boyce–Codd-normaalimuoto, johon tutustumme seuraavaksi.
Boyce–Codd-normaalimuoto
Relaatio toteuttaa Boyce–Codd-normaalimuodon, jos jokaisessa siinä olevassa funktionaalisessa riippuvuudessa \(X \to Y\) pätee, että \(Y \subset X\) tai \(X\) on yliavain.
Ideana on varmistaa, että relaatiossa ei ole riippuvuuksia, jotka eivät liittyisi relaation avaimiin. Jos tällaisia riippuvuuksia on olemassa, ne tulisi esittää erillisessä relaatiossa.
Jos \(Y \subset X\), niin attribuutit \(Y\) ovat osa attribuutteja \(X\). Tällainen riippuvuus on voimassa aina, eli se ei kerro mitään erityistä. Esimerkki tästä on riippuvuus (nimi, hinta) \(\to\) hinta.
Jos \(X\) on yliavain, niin riippuvuus \(X \to Y\) kuuluu asiaan, koska yliavain määrää kaikki attribuutit. Esimerkki tästä on riippuvuus id \(\to\) nimi.
Jos relaatio toteuttaa Boyce–Codd-normaalimuodon, niin se toteuttaa myös ensimmäisen, toisen ja kolmannen normaalimuodon.
Esimerkki
Tarkastellaan esimerkkinä seuraavaa taulua Suoritukset, jossa on kurssisuorituksia:
| Suoritukset | |||
|---|---|---|---|
| id | opiskelija_id | kurssi_id | op |
| 1 | 123123 | 111 | 5 |
| 2 | 321321 | 111 | 5 |
| 3 | 123123 | 222 | 10 |
| 4 | 321321 | 333 | 5 |
Oletetaan, että jokaisella kurssilla on kiinteä opintopisteiden määrä, jolloin taulussa on riippuvuus kurssi_id \(\to\) op. Tämä on vastoin Boyce–Codd-normaalimuotoa, koska sarake op ei ole osa saraketta kurssi_id eikä sarake kurssi_id ole yliavain.
Asia voidaan korjata tallentamalla kurssien opintopisteet erilliseen tauluun:
| Suoritukset | ||
|---|---|---|
| id | opiskelija_id | kurssi_id |
| 1 | 123123 | 111 |
| 2 | 321321 | 111 |
| 3 | 123123 | 222 |
| 4 | 321321 | 333 |
| Kurssit | |
|---|---|
| id | op |
| 111 | 5 |
| 222 | 10 |
| 333 | 5 |
Tämän muutoksen jälkeen molemmat taulut noudattavat Boyce–Codd-normaalimuotoa.
Teoria vs. käytäntö
Normaalimuotojen merkityksenä on, että ne antavat matemaattisen näkökulman tietokantojen suunnitteluun. Esimerkiksi jos tietokanta ei toteuta Boyce–Codd-normaalimuotoa, tietokannan rakennetta voi luultavasti parantaa.
Käytännössä tietokantoja ei kuitenkaan yleensä suunnitella normaalimuotojen avulla vaan luvun 6 periaatteiden tyylisesti. Normaalimuodot kuvaavat osan siitä, millainen ajattelutapa on pätevällä tietokantojen suunnittelijalla.